 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning of Optimal Individualized Treatment Rules for Heteroscedastic or Misspecified Treatment-Free Effect Models
Paper and Code
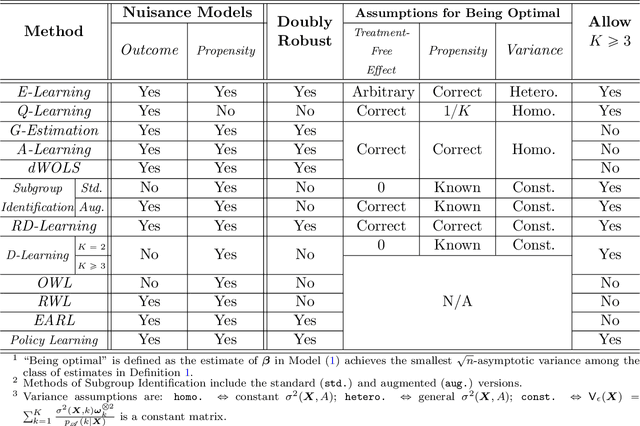
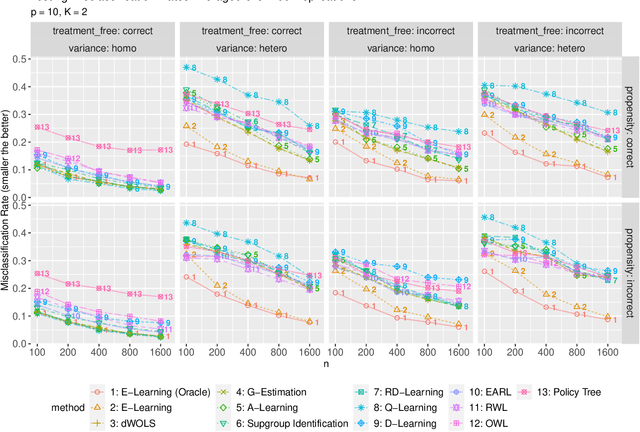

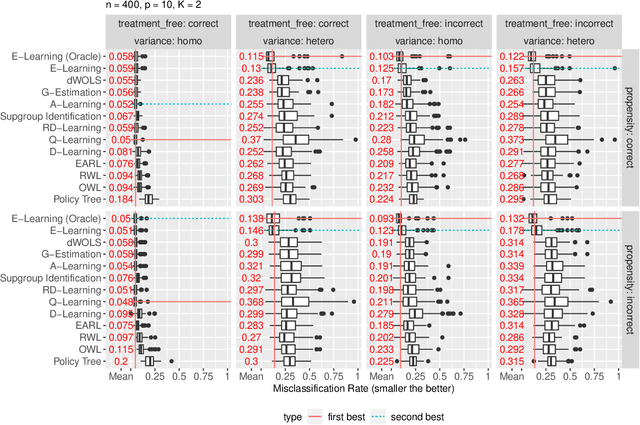
Recent development in data-driven decision science has seen great advances in individualized decision making. Given data with individual covariates, treatment assignments and outcomes, researchers can search for the optimal individualized treatment rule (ITR) that maximizes the expected outcome. Existing methods typically require initial estimation of some nuisance models. The double robustness property that can protect from misspecification of either the treatment-free effect or the propensity score has been widely advocated. However, when model misspecification exists, a doubly robust estimate can be consistent but may suffer from downgraded efficiency. Other than potential misspecified nuisance models, most existing methods do not account for the potential problem when the variance of outcome is heterogeneous among covariates and treatment. We observe that such heteroscedasticity can greatly affect the estimation efficiency of the optimal ITR. In this paper, we demonstrate that the consequences of misspecified treatment-free effect and heteroscedasticity can be unified as a covariate-treatment dependent variance of residuals. To improve efficiency of the estimated ITR, we propose an Efficient Learning (E-Learning) framework for finding an optimal ITR in the multi-armed treatment setting. We show that the proposed E-Learning is optimal among a regular class of semiparametric estimates that can allow treatment-free effect misspecification. In our simulation study, E-Learning demonstrates its effectiveness if one of or both misspecified treatment-free effect and heteroscedasticity exist. Our analysis of a Type 2 Diabetes Mellitus (T2DM) observational study also suggests the improved efficiency of E-Learning.