 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Have Been Learned & What Should Be Learned? An Empirical Study of How to Selectively Augment Text for Classification
Paper and Code
Sep 01, 2021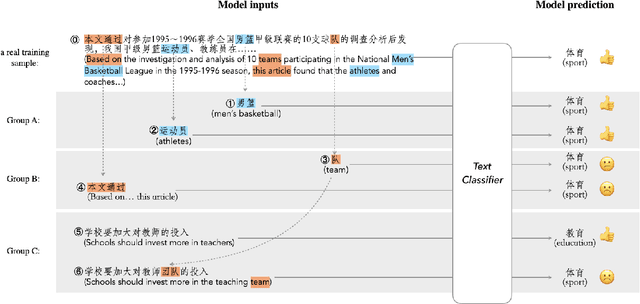
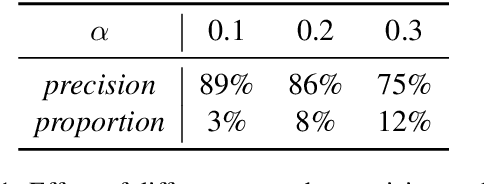
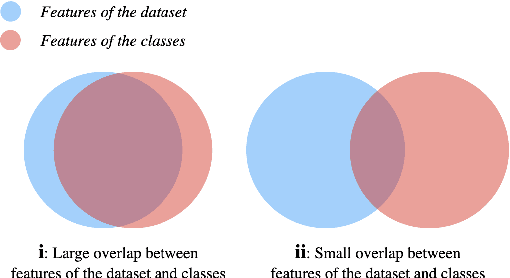
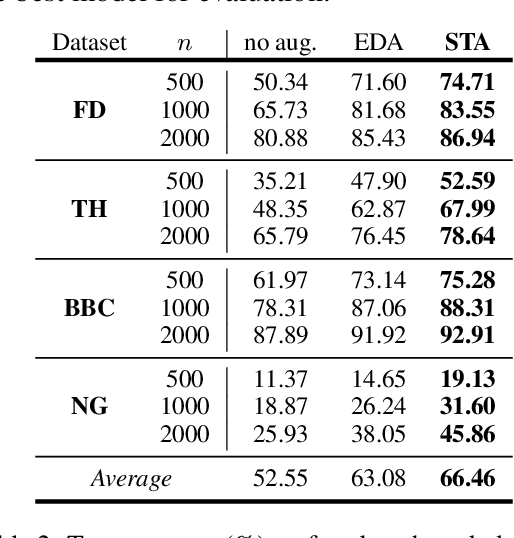
Text augmentation techniques are widely used in text classification problems to improve the performance of classifiers, especially in low-resource scenarios. Whilst lots of creative text augmentation methods have been designed, they augment the text in a non-selective manner, which means the less important or noisy words have the same chances to be augmented as the informative words, and thereby limits the performance of augmentation. In this work, we systematically summarize three kinds of role keywords, which have different functions for text classification, and design effective methods to extract them from the text. Based on these extracted role keywords, we propose STA (Selective Text Augmentation) to selectively augment the text, where the informative, class-indicating words are emphasized but the irrelevant or noisy words are diminished. Extensive experiments on four English and Chinese text classification benchmark datasets demonstrate that STA can substantially outperform the non-selective text augmentation methods.