 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact representations of convolutional neural networks via weight pruning and quantization
Paper and Code
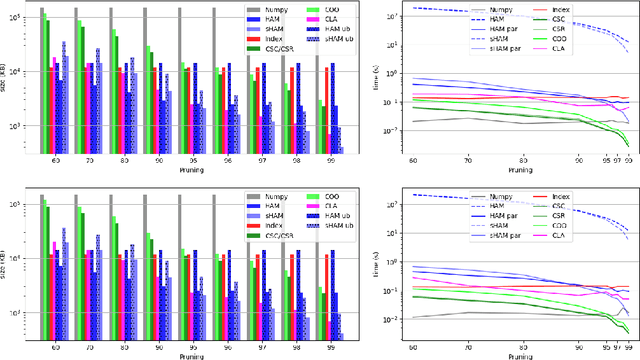
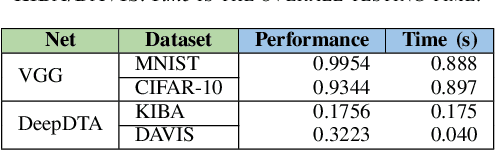
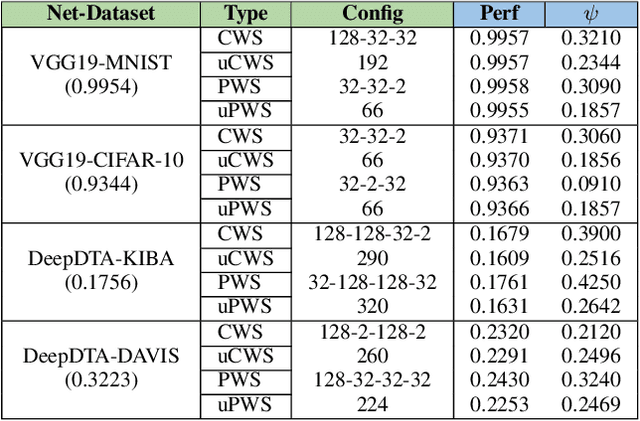
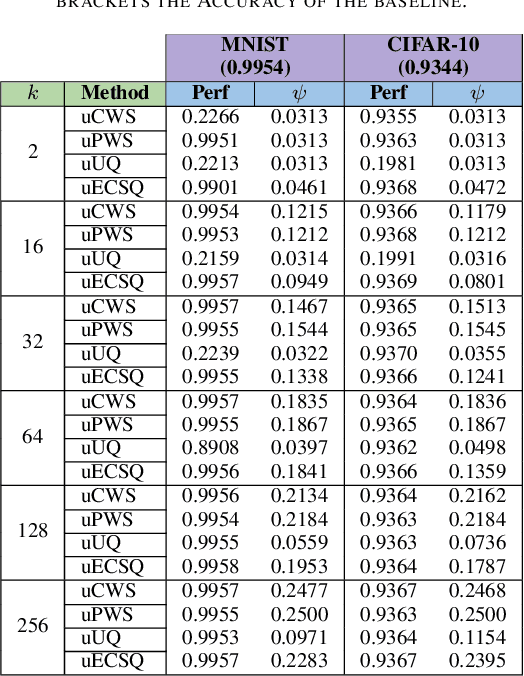
The state-of-the-art performance for several real-world problems is currently reached by convolutional neural networks (CNN). Such learning models exploit recent results in the field of deep learning, typically leading to highly performing, yet very large neural networks with (at least) millions of parameters. As a result, the deployment of such models is not possible when only small amounts of RAM are available, or in general within resource-limited platforms, and strategies to compress CNNs became thus of paramount importance. In this paper we propose a novel lossless storage format for CNNs based on source coding and leveraging both weight pruning and quantization. We theoretically derive the space upper bounds for the proposed structures, showing their relationship with both sparsity and quantization levels of the weight matrices. Both compression rates and excution times have been tested against reference methods for matrix compression, and an empirical evaluation of state-of-the-art quantization schemes based on weight sharing is also discussed, to assess their impact on the performance when applied to both convolutional and fully connected layers. On four benchmarks for classification and regression problems and comparing to the baseline pre-trained uncompressed network, we achieved a reduction of space occupancy up to 0.6% on fully connected layers and 5.44% on the whole network, while performing at least as competitive as the baseline.