 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Realistic Study of Auto-regressive Language Models for Named Entity Typing and Recognition
Paper and Code
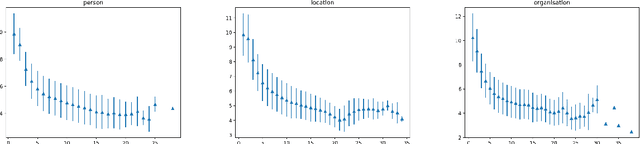


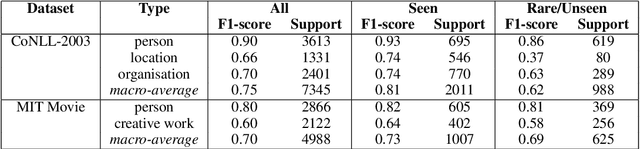
Despite impressive results of language models for named entity recognition (NER), their generalization to varied textual genres, a growing entity type set, and new entities remains a challenge. Collecting thousands of annotations in each new case for training or fine-tuning is expensive and time-consuming. In contrast, humans can easily identify named entities given some simple instructions. Inspired by this, we challenge the reliance on large datasets and study pre-trained language models for NER in a meta-learning setup. First, we test named entity typing (NET) in a zero-shot transfer scenario. Then, we perform NER by giving few examples at inference. We propose a method to select seen and rare / unseen names when having access only to the pre-trained model and report results on these groups. The results show: auto-regressive language models as meta-learners can perform NET and NER fairly well especially for regular or seen names; name irregularity when often present for a certain entity type can become an effective exploitable cue; names with words foreign to the model have the most negative impact on results; the model seems to rely more on name than context cues in few-shot NER.