 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statutory Article Retrieval Dataset in French
Paper and Code
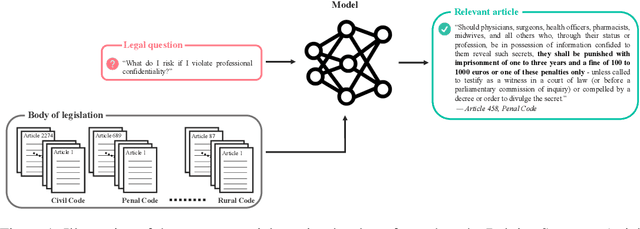
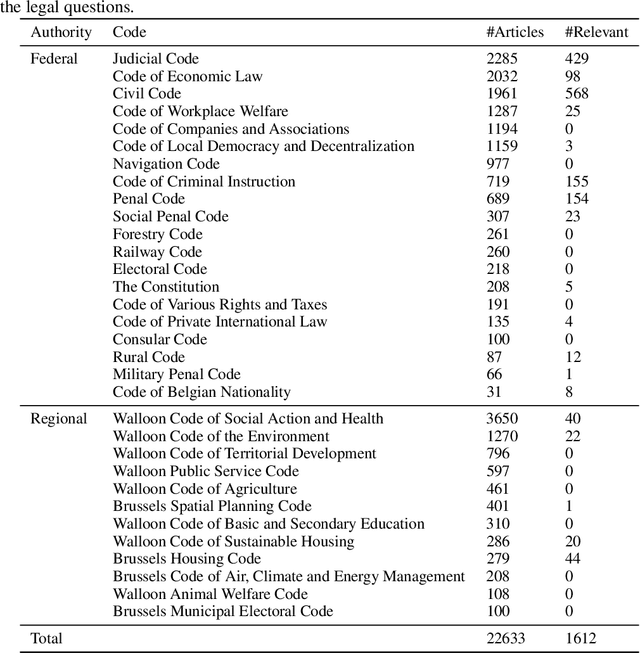

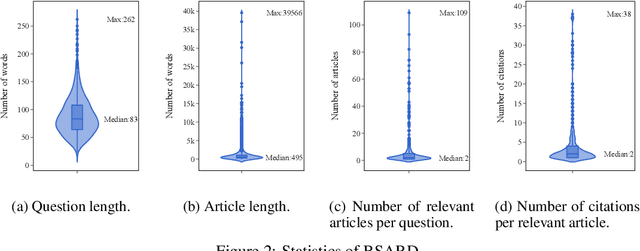
Statutory article retrieval is the task of automatically retrieving law articles relevant to a legal question. While recent advances in natural language processing have sparked considerable interest in many legal tasks, statutory article retrieval remains primarily untouched due to the scarcity of large-scale and high-quality annotated datasets. To address this bottleneck, we introduce the Belgian Statutory Article Retrieval Dataset (BSARD), which consists of 1,100+ French native legal questions labeled by experienced jurists with relevant articles from a corpus of 22,600+ Belgian law articles. Using BSARD, we benchmark several unsupervised information retrieval methods based on term weighting and pooled embeddings. Our best performing baseline achieves 50.8% R@100, which is promising for the feasibility of the task and indicates that there is still substantial room for improvement. By the specificity of the data domain and addressed task, BSARD presents a unique challenge problem for future research on legal information retrieval.