 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing BERT Encoding and Sentence-Level Language Model for Sentence Ordering
Paper and Code
Aug 24, 2021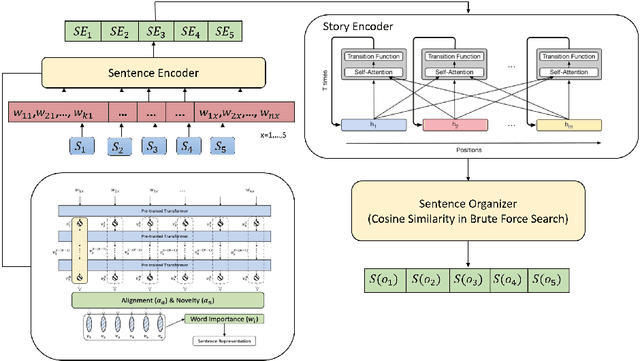


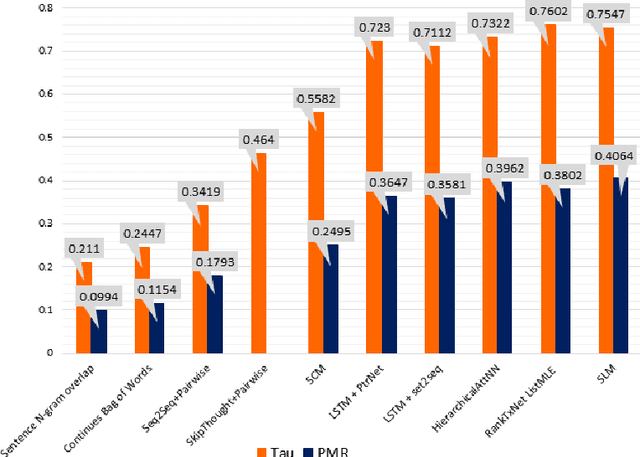
Discovering the logical sequence of events is one of the cornerstones in Natural Language Understanding. One approach to learn the sequence of events is to study the order of sentences in a coherent text. Sentence ordering can be applied in various tasks such as retrieval-based Question Answering, document summarization, storytelling, text generation, and dialogue systems. Furthermore, we can learn to model text coherence by learning how to order a set of shuffled sentences. Previous research has relied on RNN, LSTM, and BiLSTM architecture for learning text language models. However, these networks have performed poorly due to the lack of attention mechanisms. We propose an algorithm for sentence ordering in a corpus of short stories. Our proposed method uses a language model based on Universal Transformers (UT) that captures sentences' dependencies by employing an attention mechanism. Our method improves the previous state-of-the-art in terms of Perfect Match Ratio (PMR) score in the ROCStories dataset, a corpus of nearly 100K short human-made stories. The proposed model includes three components: Sentence Encoder, Language Model, and Sentence Arrangement with Brute Force Search. The first component generates sentence embeddings using SBERT-WK pre-trained model fine-tuned on the ROCStories data. Then a Universal Transformer network generates a sentence-level language model. For decoding, the network generates a candidate sentence as the following sentence of the current sentence. We use cosine similarity as a scoring function to assign scores to the candidate embedding and the embeddings of other sentences in the shuffled set. Then a Brute Force Search is employed to maximize the sum of similarities between pairs of consecutive sentences.