 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGEMs: A Metric Model for Automatic Code Generation using GPT-3
Paper and Code
Aug 23, 2021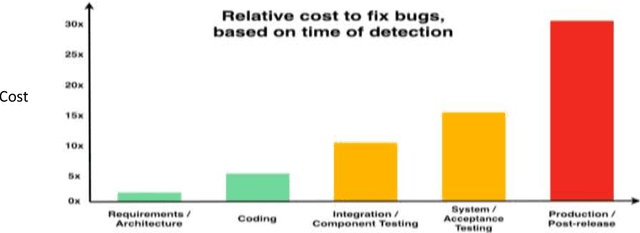
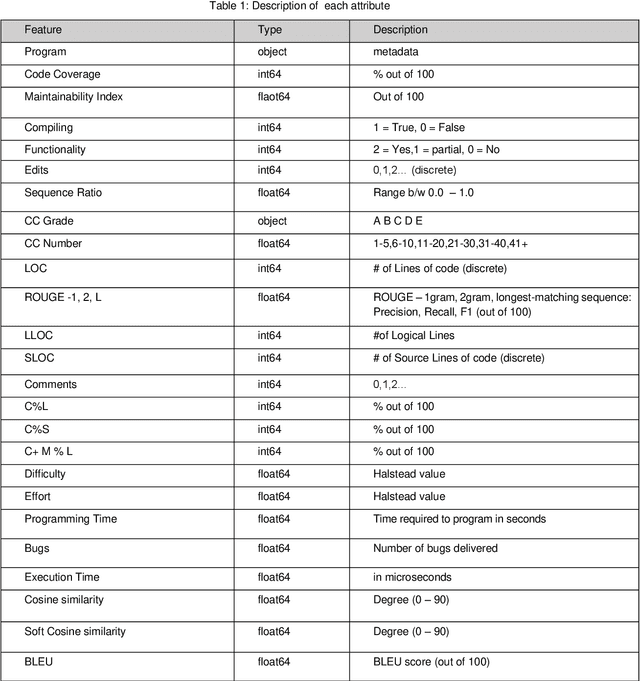
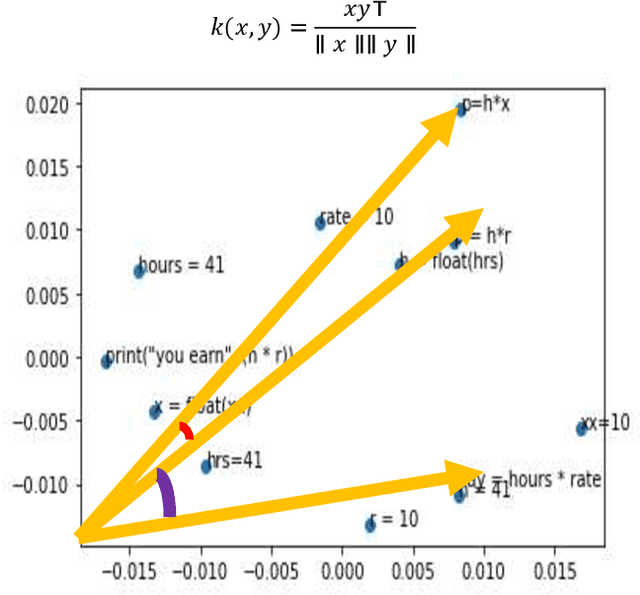

Today, AI technology is showing its strengths in almost every industry and walks of life. From text generation, text summarization, chatbots, NLP is being used widely. One such paradigm is automatic code generation. An AI could be generating anything; hence the output space is unconstrained. A self-driving car is driven for 100 million miles to validate its safety, but tests cannot be written to monitor and cover an unconstrained space. One of the solutions to validate AI-generated content is to constrain the problem and convert it from abstract to realistic, and this can be accomplished by either validating the unconstrained algorithm using theoretical proofs or by using Monte-Carlo simulation methods. In this case, we use the latter approach to test/validate a statistically significant number of samples. This hypothesis of validating the AI-generated code is the main motive of this work and to know if AI-generated code is reliable, a metric model CGEMs is proposed. This is an extremely challenging task as programs can have different logic with different naming conventions, but the metrics must capture the structure and logic of the program. This is similar to the importance grammar carries in AI-based text generation, Q&A, translations, etc. The various metrics that are garnered in this work to support the evaluation of generated code are as follows: Compilation, NL description to logic conversion, number of edits needed, some of the commonly used static-code metrics and NLP metrics. These metrics are applied to 80 codes generated using OpenAI's GPT-3. Post which a Neural network is designed for binary classification (acceptable/not acceptable quality of the generated code). The inputs to this network are the values of the features obtained from the metrics. The model achieves a classification accuracy of 76.92% and an F1 score of 55.56%. XAI is augmented for model interpretability.