 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Learning on Keywords for Efficient FAQ Retrieval
Paper and Code
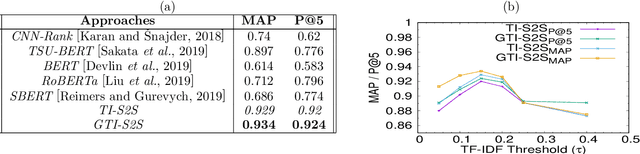
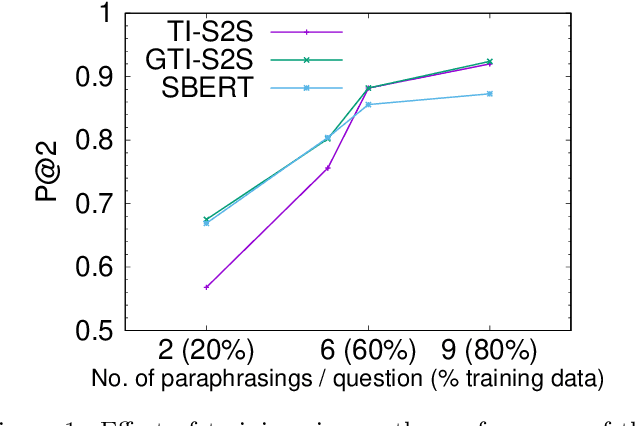
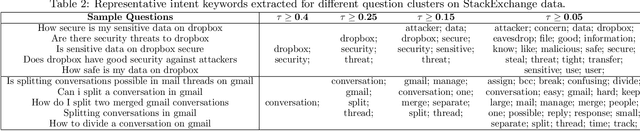
Frequently-Asked-Question (FAQ) retrieval provides an effective procedure for responding to user's natural language based queries. Such platforms are becoming common in enterprise chatbots, product question answering, and preliminary technical support for customers. However, the challenge in such scenarios lies in bridging the lexical and semantic gap between varied query formulations and the corresponding answers, both of which typically have a very short span. This paper proposes TI-S2S, a novel learning framework combining TF-IDF based keyword extraction and Word2Vec embeddings for training a Sequence-to-Sequence (Seq2Seq) architecture. It achieves high precision for FAQ retrieval by better understanding the underlying intent of a user question captured via the representative keywords. We further propose a variant with an additional neural network module for guiding retrieval via relevant candidate identification based on similarity features. Experiments on publicly available dataset depict our approaches to provide around 92% precision-at-rank-5, exhibiting nearly 13% improvement over existing approaches.