 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Bootstrap Inference For Policy Evaluation in Reinforcement Learning
Paper and Code
Aug 08, 2021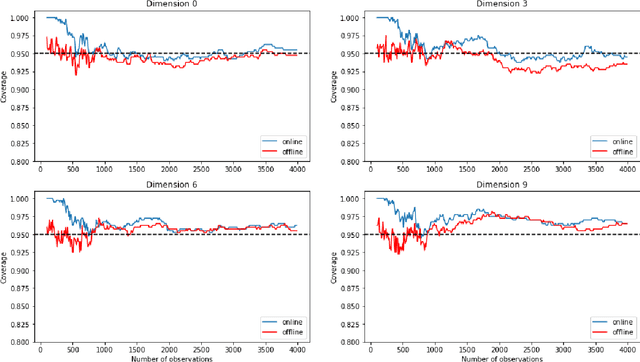
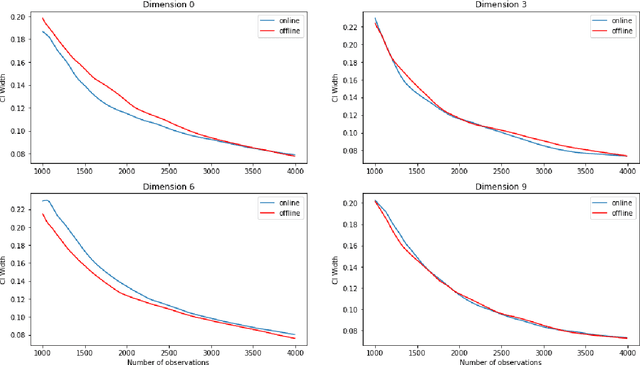
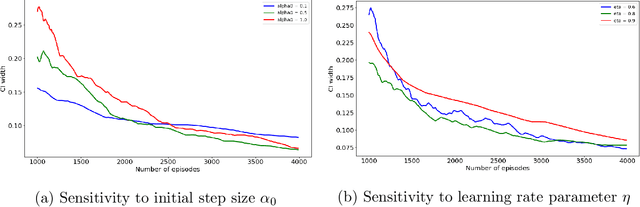
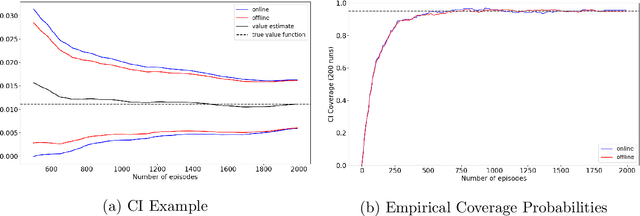
The recent emergence of reinforcement learning has created a demand for robust statistical inference methods for the parameter estimates computed using these algorithms. Existing methods for statistical inference in online learning are restricted to settings involving independently sampled observations, while existing statistical inference methods in reinforcement learning (RL) are limited to the batch setting. The online bootstrap is a flexible and efficient approach for statistical inference in linear stochastic approximation algorithms, but its efficacy in settings involving Markov noise, such as RL, has yet to be explored. In this paper, we study the use of the online bootstrap method for statistical inference in RL. In particular, we focus on the temporal difference (TD) learning and Gradient TD (GTD) learning algorithms, which are themselves special instances of linear stochastic approximation under Markov noise. The method is shown to be distributionally consistent for statistical inference in policy evaluation, and numerical experiments are included to demonstrate the effectiveness of this algorithm at statistical inference tasks across a range of real RL environments.