 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Differentially Private BERT
Paper and Code

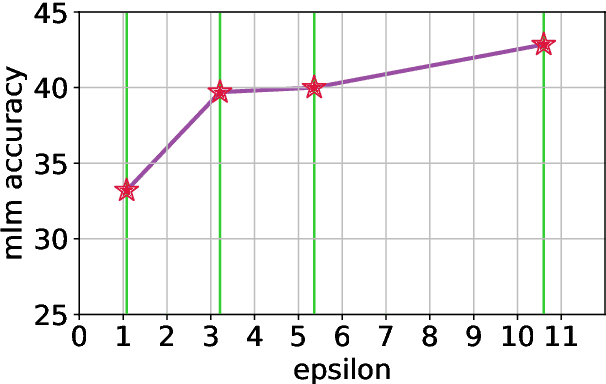
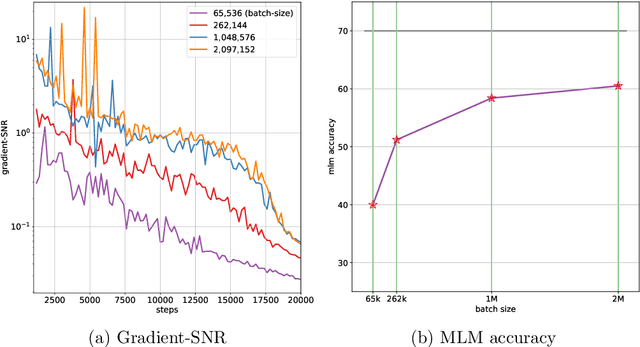
In this work, we study the large-scale pretraining of BERT-Large with differentially private SGD (DP-SGD). We show that combined with a careful implementation, scaling up the batch size to millions (i.e., mega-batches) improves the utility of the DP-SGD step for BERT; we also enhance its efficiency by using an increasing batch size schedule. Our implementation builds on the recent work of [SVK20], who demonstrated that the overhead of a DP-SGD step is minimized with effective use of JAX [BFH+18, FJL18] primitives in conjunction with the XLA compiler [XLA17]. Our implementation achieves a masked language model accuracy of 60.5% at a batch size of 2M, for $\epsilon = 5.36$. To put this number in perspective, non-private BERT models achieve an accuracy of $\sim$70%.