 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Depth of Moving Objects in Video
Paper and Code
Aug 02, 2021
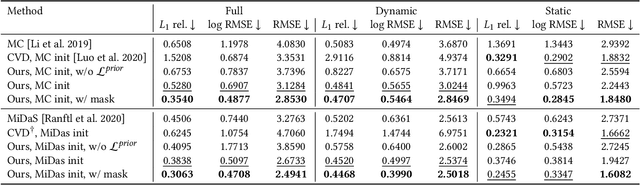
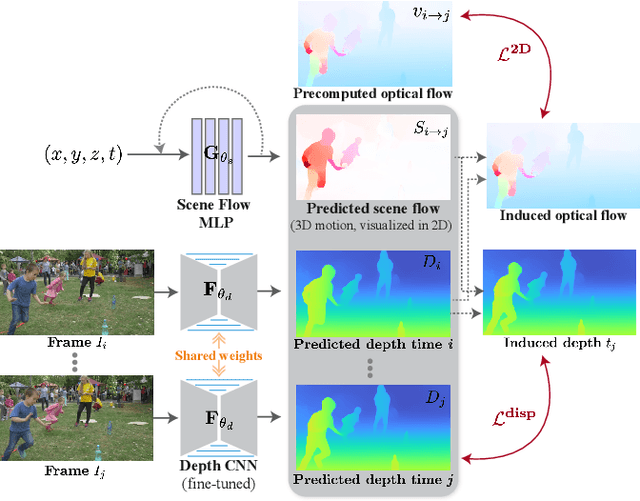
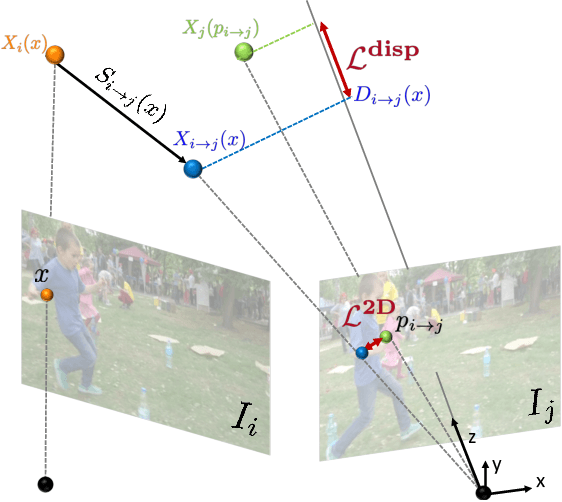
We present a method to estimate depth of a dynamic scene, containing arbitrary moving objects, from an ordinary video captured with a moving camera. We seek a geometrically and temporally consistent solution to this underconstrained problem: the depth predictions of corresponding points across frames should induce plausible, smooth motion in 3D. We formulate this objective in a new test-time training framework where a depth-prediction CNN is trained in tandem with an auxiliary scene-flow prediction MLP over the entire input video. By recursively unrolling the scene-flow prediction MLP over varying time steps, we compute both short-range scene flow to impose local smooth motion priors directly in 3D, and long-range scene flow to impose multi-view consistency constraints with wide baselines. We demonstrate accurate and temporally coherent results on a variety of challenging videos containing diverse moving objects (pets, people, cars), as well as camera motion. Our depth maps give rise to a number of depth-and-motion aware video editing effects such as object and lighting insertion.