 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Federated Multi-agent Architecture for Networked Connected Communication Network
Paper and Code
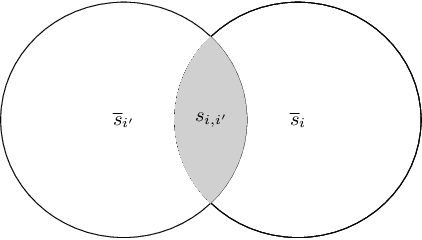
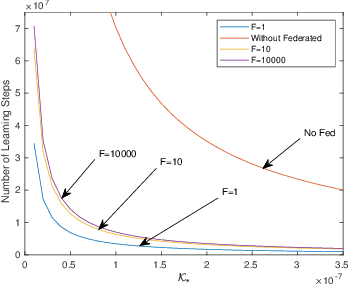
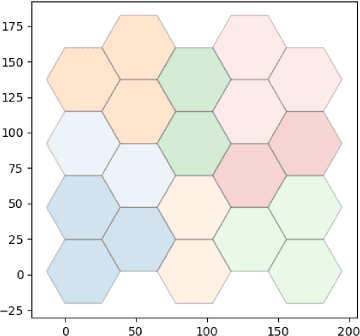
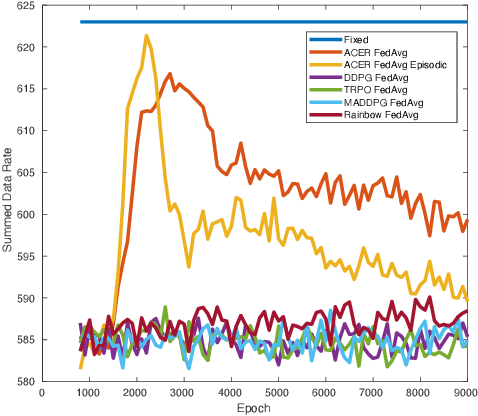
Scalability is the key roadstone towards the application of cooperative intelligent algorithms in large-scale networks. Reinforcement learning (RL) is known as model-free and high efficient intelligent algorithm for communication problems and proved useful in the communication network. However, when coming to large-scale networks with limited centralization, it is not possible to employ a centralized entity to perform joint real-time decision making for entire network. This introduces the scalability challenges, while multi-agent reinforcement shows the opportunity to cope this challenges and extend the intelligent algorithm to cooperative large-scale network. In this paper, we introduce the federated mean-field multi-agent reinforcement learning structure to capture the problem in large scale multi-agent communication scenarios, where agents share parameters to form consistency. We present the theoretical basis of our architecture and show the influence of federated frequency with an informational multi-agent model. We then exam the performance of our architecture with a coordinated multi-point environment which requires handshakes between neighbour access-points to realise the cooperation gain. Our result shows that the learning structure can effectively solve the cooperation problem in a large scale network with decent scalability. We also show the effectiveness of federated algorithms and highlight the importance of maintaining personality in each access-point.