 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategically Efficient Exploration in Competitive Multi-agent Reinforcement Learning
Paper and Code
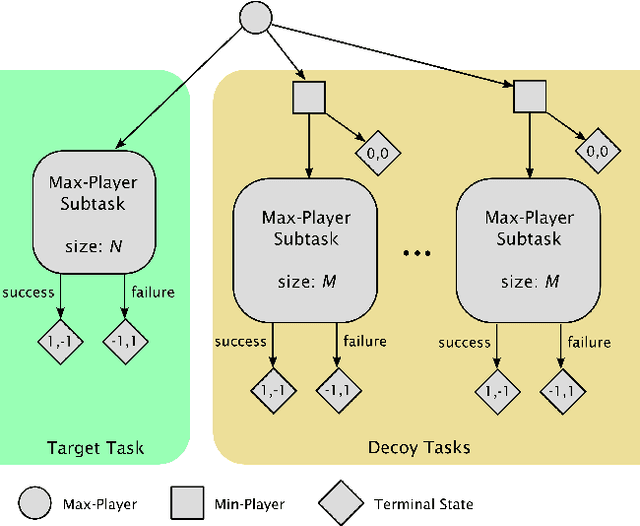
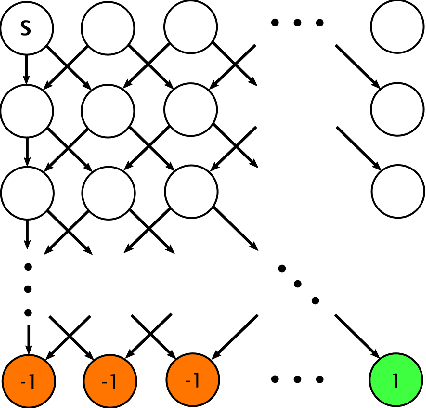
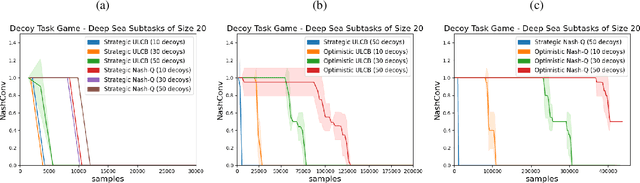
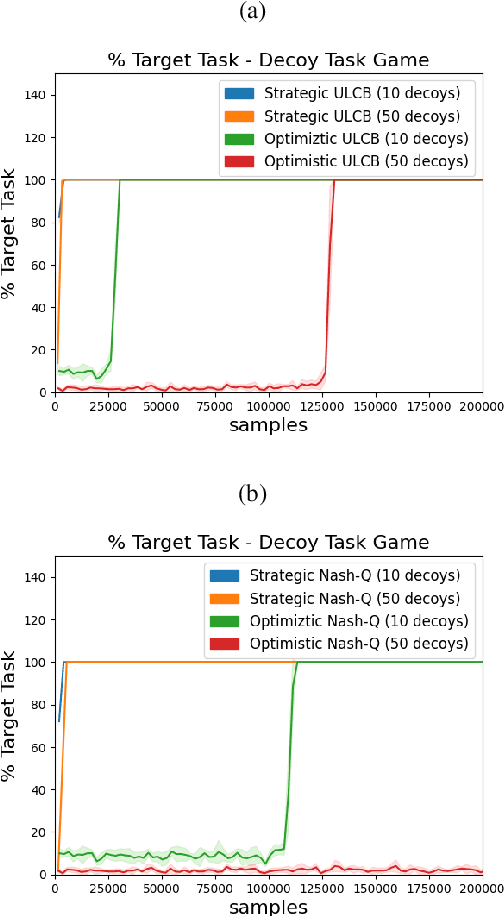
High sample complexity remains a barrier to the application of reinforcement learning (RL), particularly in multi-agent systems. A large body of work has demonstrated that exploration mechanisms based on the principle of optimism under uncertainty can significantly improve the sample efficiency of RL in single agent tasks. This work seeks to understand the role of optimistic exploration in non-cooperative multi-agent settings. We will show that, in zero-sum games, optimistic exploration can cause the learner to waste time sampling parts of the state space that are irrelevant to strategic play, as they can only be reached through cooperation between both players. To address this issue, we introduce a formal notion of strategically efficient exploration in Markov games, and use this to develop two strategically efficient learning algorithms for finite Markov games. We demonstrate that these methods can be significantly more sample efficient than their optimistic counterparts.