 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn automated domain-independent text reading, interpreting and extracting approach for reviewing the scientific literature
Paper and Code
Aug 04, 2021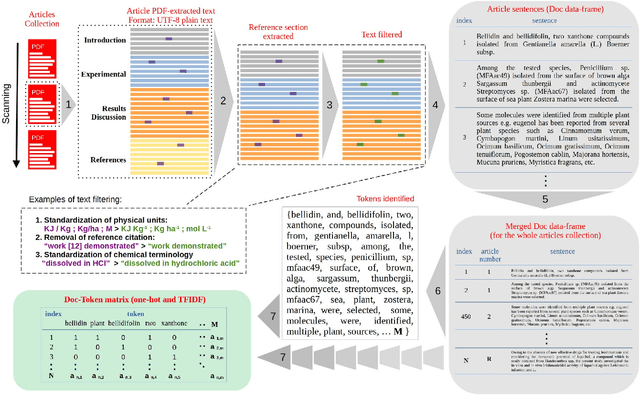
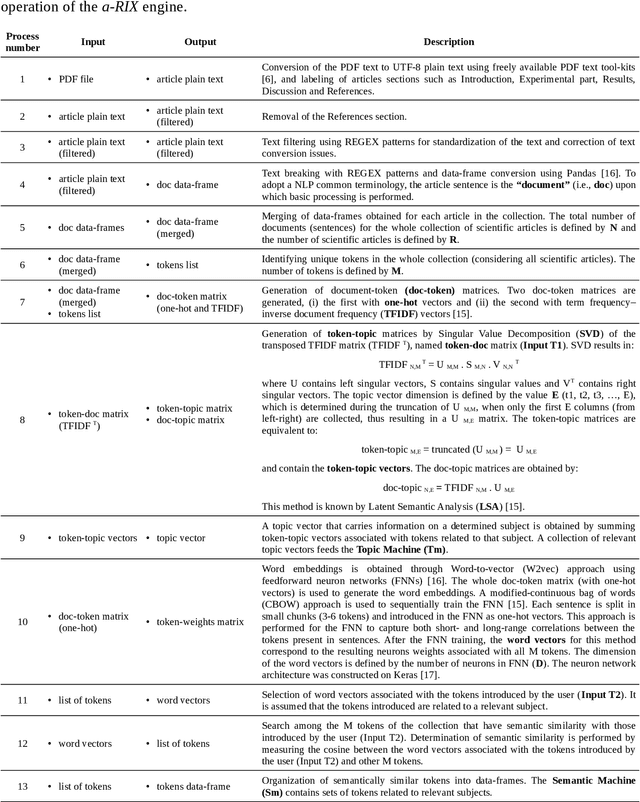
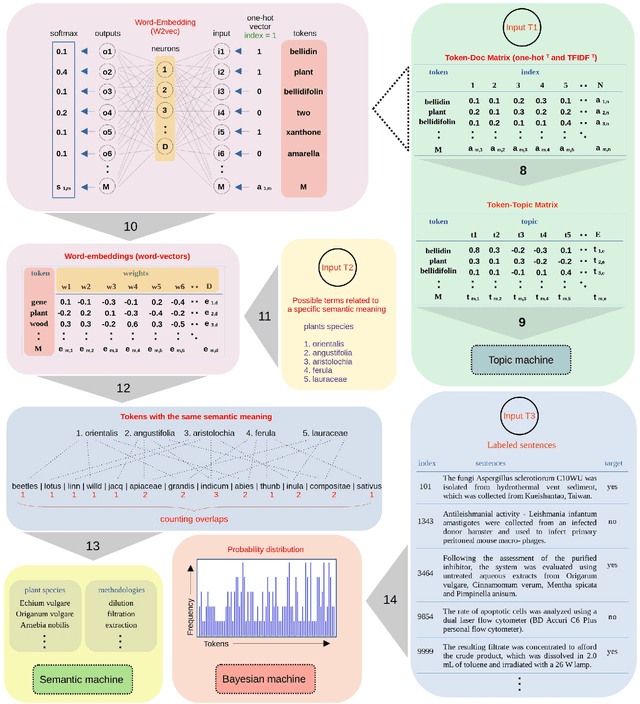
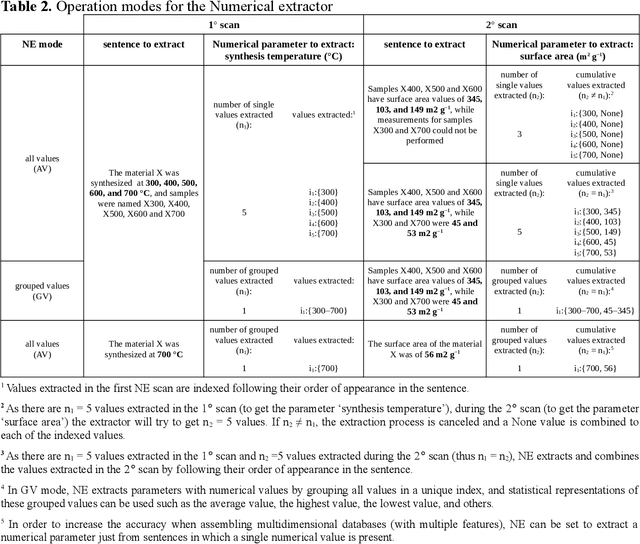
It is presented here a machine learning-based (ML) natural language processing (NLP) approach capable to automatically recognize and extract categorical and numerical parameters from a corpus of articles. The approach (named a.RIX) operates with a concomitant/interchangeable use of ML models such as neuron networks (NNs), latent semantic analysis (LSA), naive-Bayes classifiers (NBC), and a pattern recognition model using regular expression (REGEX). A corpus of 7,873 scientific articles dealing with natural products (NPs) was used to demonstrate the efficiency of the a.RIX engine. The engine automatically extracts categorical and numerical parameters such as (i) the plant species from which active molecules are extracted, (ii) the microorganisms species for which active molecules can act against, and (iii) the values of minimum inhibitory concentration (MIC) against these microorganisms. The parameters are extracted without part-of-speech tagging (POS) and named entity recognition (NER) approaches (i.e. without the need of text annotation), and the models training is performed with unsupervised approaches. In this way, a.RIX can be essentially used on articles from any scientific field. Finally, it can potentially make obsolete the current article reviewing process in some areas, especially those in which machine learning models capture texts structure, text semantics, and latent knowledge.