 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments
Paper and Code
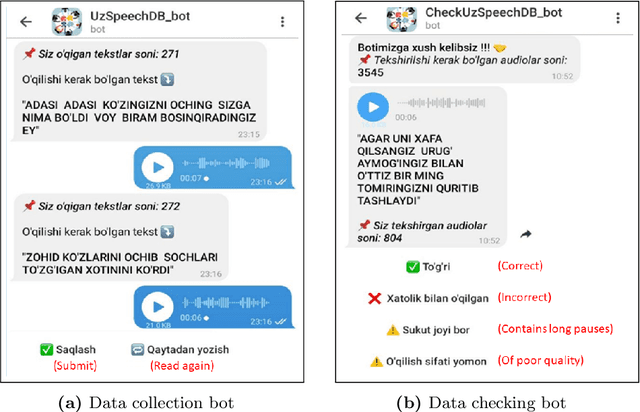
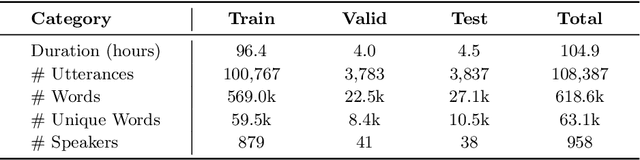
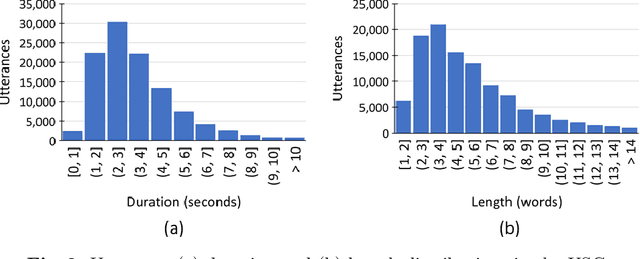
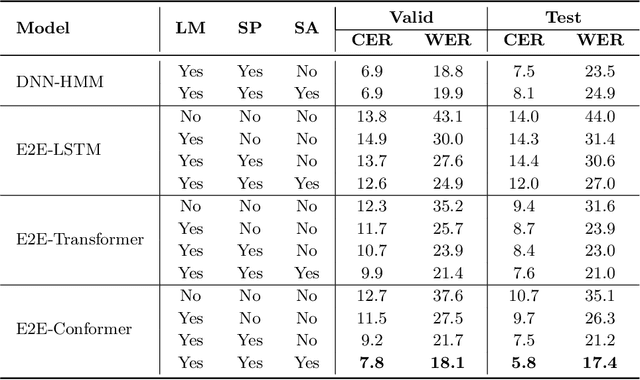
We present a freely available speech corpus for the Uzbek language and report preliminary automatic speech recognition (ASR) results using both the deep neural network hidden Markov model (DNN-HMM) and end-to-end (E2E) architectures. The Uzbek speech corpus (USC) comprises 958 different speakers with a total of 105 hours of transcribed audio recordings. To the best of our knowledge, this is the first open-source Uzbek speech corpus dedicated to the ASR task. To ensure high quality, the USC has been manually checked by native speakers. We first describe the design and development procedures of the USC, and then explain the conducted ASR experiments in detail. The experimental results demonstrate promising results for the applicability of the USC for ASR. Specifically, 18.1% and 17.4% word error rates were achieved on the validation and test sets, respectively. To enable experiment reproducibility, we share the USC dataset, pre-trained models, and training recipes in our GitHub repository.