 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Sweep your Learning Rate under the Rug: A Closer Look at Cross-modal Transfer of Pretrained Transformers
Paper and Code
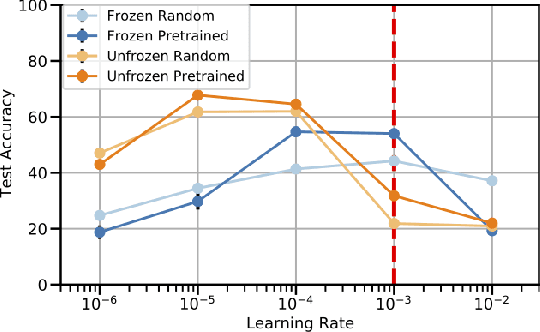

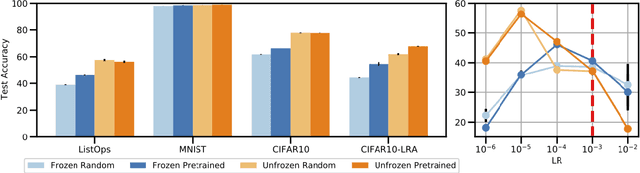

Self-supervised pre-training of large-scale transformer models on text corpora followed by finetuning has achieved state-of-the-art on a number of natural language processing tasks. Recently, Lu et al. (2021, arXiv:2103.05247) claimed that frozen pretrained transformers (FPTs) match or outperform training from scratch as well as unfrozen (fine-tuned) pretrained transformers in a set of transfer tasks to other modalities. In our work, we find that this result is, in fact, an artifact of not tuning the learning rates. After carefully redesigning the empirical setup, we find that when tuning learning rates properly, pretrained transformers do outperform or match training from scratch in all of our tasks, but only as long as the entire model is finetuned. Thus, while transfer from pretrained language models to other modalities does indeed provide gains and hints at exciting possibilities for future work, properly tuning hyperparameters is important for arriving at robust findings.