 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal2Global: Scaling global representation learning on graphs via local training
Paper and Code
Jul 26, 2021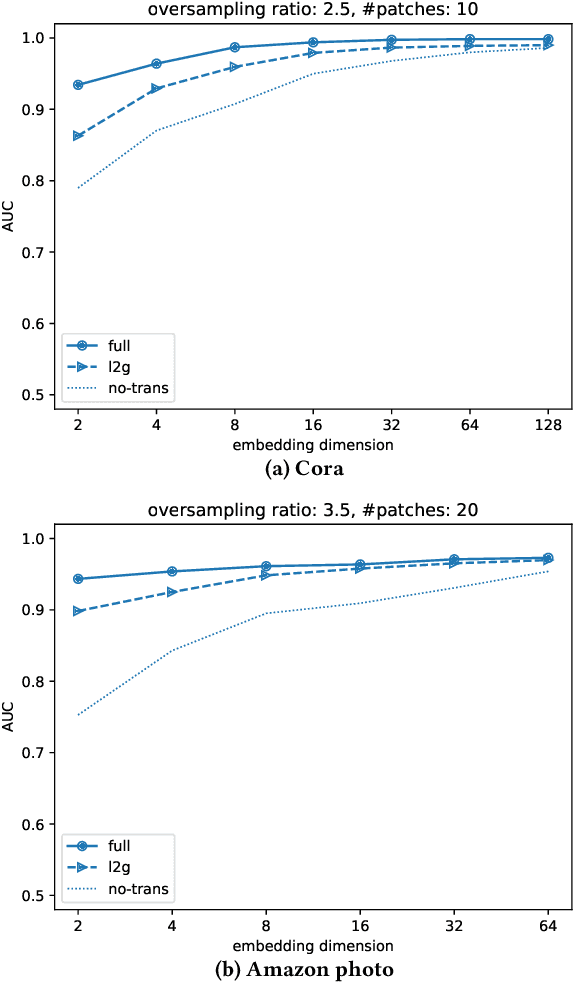
We propose a decentralised "local2global" approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronisation during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. Preliminary results on medium-scale data sets (up to $\sim$7K nodes and $\sim$200K edges) are promising, with a graph reconstruction performance for local2global that is comparable to that of globally trained embeddings. A thorough evaluation of local2global on large scale data and applications to downstream tasks, such as node classification and link prediction, constitutes ongoing work.