 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregate or Not? Exploring Where to Privatize in DNN Based Federated Learning Under Different Non-IID Scenes
Paper and Code
Jul 26, 2021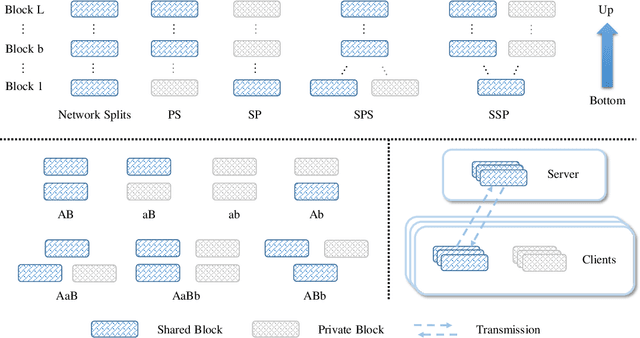

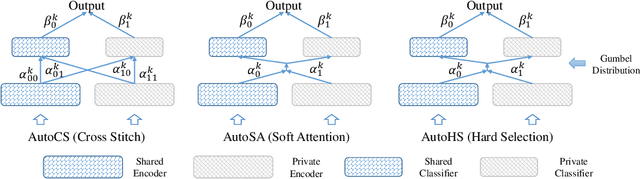
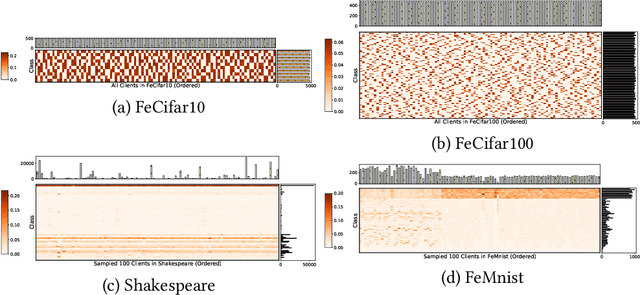
Although federated learning (FL) has recently been proposed for efficient distributed training and data privacy protection, it still encounters many obstacles. One of these is the naturally existing statistical heterogeneity among clients, making local data distributions non independently and identically distributed (i.e., non-iid), which poses challenges for model aggregation and personalization. For FL with a deep neural network (DNN), privatizing some layers is a simple yet effective solution for non-iid problems. However, which layers should we privatize to facilitate the learning process? Do different categories of non-iid scenes have preferred privatization ways? Can we automatically learn the most appropriate privatization way during FL? In this paper, we answer these questions via abundant experimental studies on several FL benchmarks. First, we present the detailed statistics of these benchmarks and categorize them into covariate and label shift non-iid scenes. Then, we investigate both coarse-grained and fine-grained network splits and explore whether the preferred privatization ways have any potential relations to the specific category of a non-iid scene. Our findings are exciting, e.g., privatizing the base layers could boost the performances even in label shift non-iid scenes, which are inconsistent with some natural conjectures. We also find that none of these privatization ways could improve the performances on the Shakespeare benchmark, and we guess that Shakespeare may not be a seriously non-iid scene. Finally, we propose several approaches to automatically learn where to aggregate via cross-stitch, soft attention, and hard selection. We advocate the proposed methods could serve as a preliminary try to explore where to privatize for a novel non-iid scene.