 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation and Out-of-Distribution Detection for Counterfactual Explanations: Pitfalls and Solutions
Paper and Code
Jul 20, 2021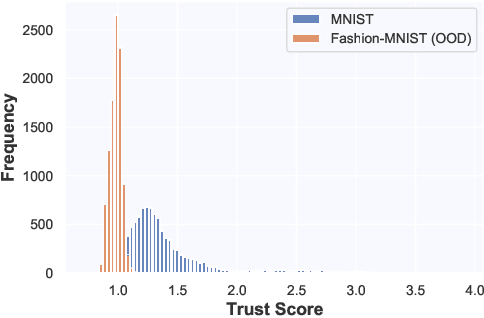
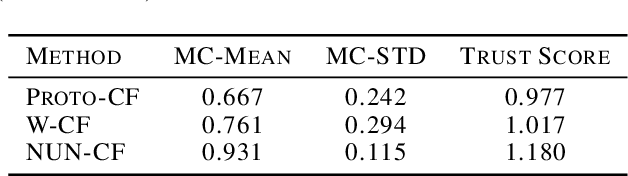
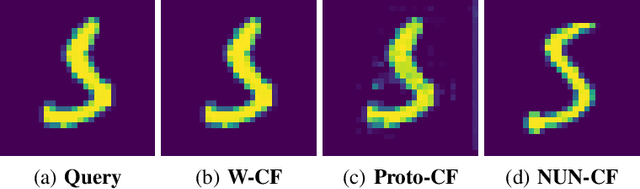
Whilst an abundance of techniques have recently been proposed to generate counterfactual explanations for the predictions of opaque black-box systems, markedly less attention has been paid to exploring the uncertainty of these generated explanations. This becomes a critical issue in high-stakes scenarios, where uncertain and misleading explanations could have dire consequences (e.g., medical diagnosis and treatment planning). Moreover, it is often difficult to determine if the generated explanations are well grounded in the training data and sensitive to distributional shifts. This paper proposes several practical solutions that can be leveraged to solve these problems by establishing novel connections with other research works in explainability (e.g., trust scores) and uncertainty estimation (e.g., Monte Carlo Dropout). Two experiments demonstrate the utility of our proposed solutions.