 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Bayesian Learning with Diagonal Quasi-Newton Method For Large Scale Classification
Paper and Code
Jul 17, 2021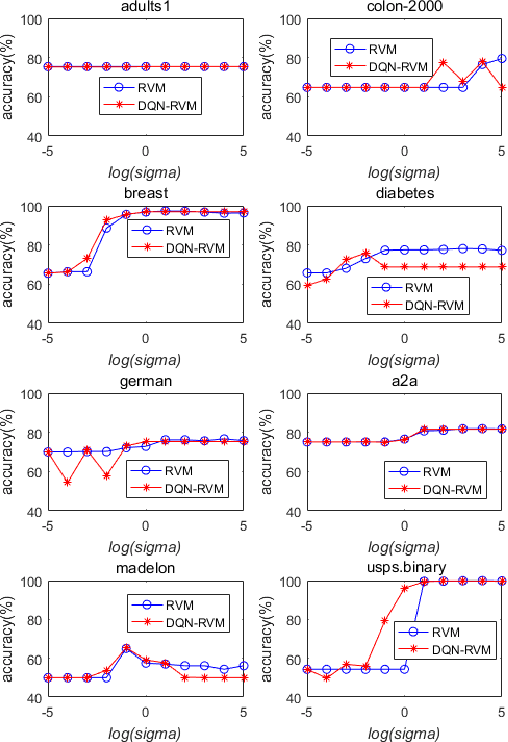
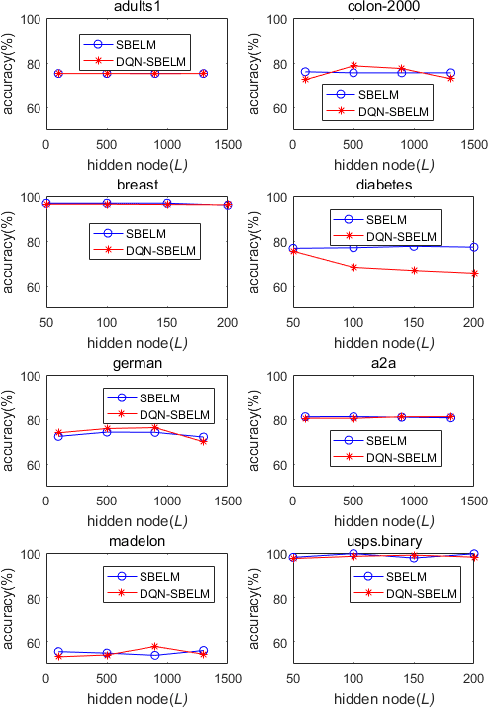
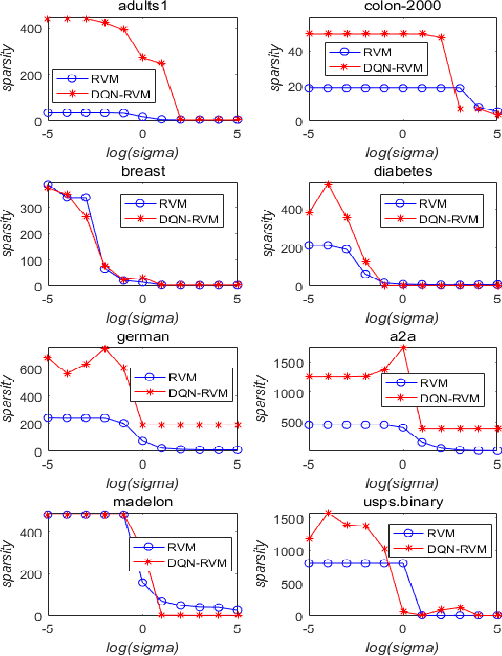
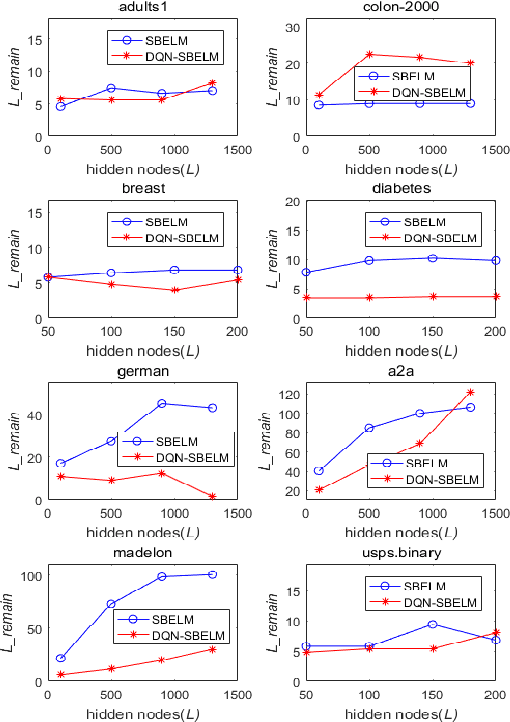
Sparse Bayesian Learning (SBL) constructs an extremely sparse probabilistic model with very competitive generalization. However, SBL needs to invert a big covariance matrix with complexity O(M^3 ) (M: feature size) for updating the regularization priors, making it difficult for practical use. There are three issues in SBL: 1) Inverting the covariance matrix may obtain singular solutions in some cases, which hinders SBL from convergence; 2) Poor scalability to problems with high dimensional feature space or large data size; 3) SBL easily suffers from memory overflow for large-scale data. This paper addresses these issues with a newly proposed diagonal Quasi-Newton (DQN) method for SBL called DQN-SBL where the inversion of big covariance matrix is ignored so that the complexity and memory storage are reduced to O(M). The DQN-SBL is thoroughly evaluated on non-linear classifiers and linear feature selection using various benchmark datasets of different sizes. Experimental results verify that DQN-SBL receives competitive generalization with a very sparse model and scales well to large-scale problems.