 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Image Translations via Ensemble Self-Supervised Learning for Unsupervised Domain Adaptation
Paper and Code
Jul 13, 2021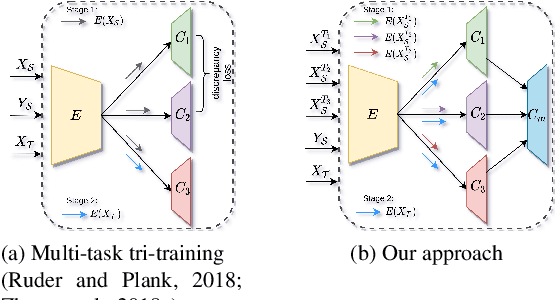
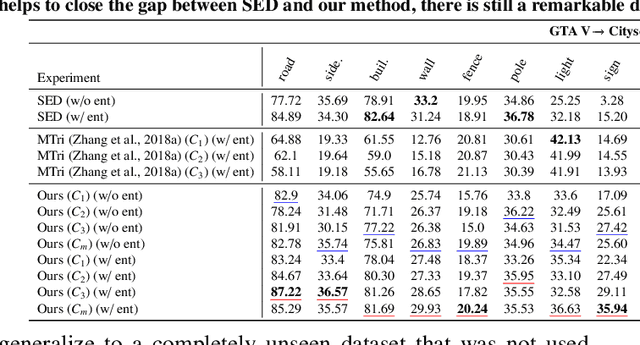
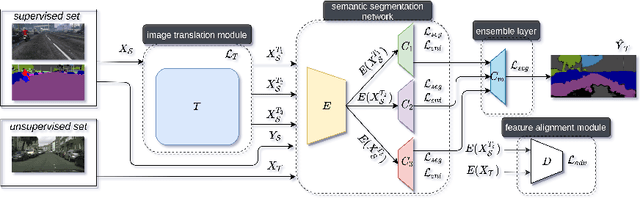
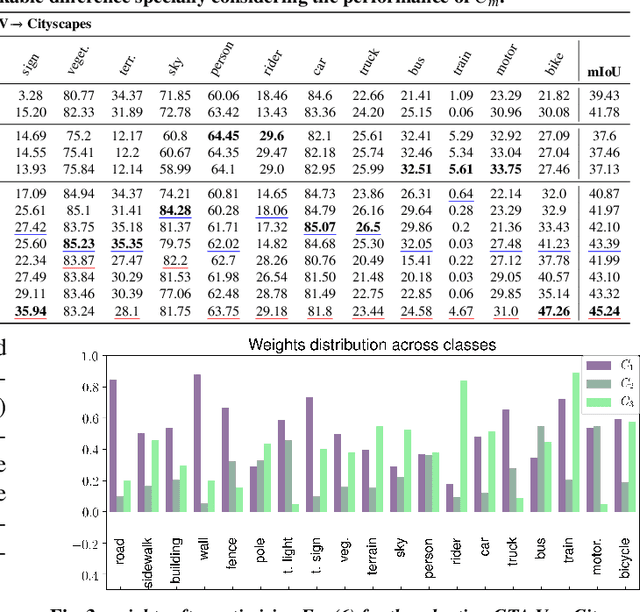
We introduce an unsupervised domain adaption (UDA) strategy that combines multiple image translations, ensemble learning and self-supervised learning in one coherent approach. We focus on one of the standard tasks of UDA in which a semantic segmentation model is trained on labeled synthetic data together with unlabeled real-world data, aiming to perform well on the latter. To exploit the advantage of using multiple image translations, we propose an ensemble learning approach, where three classifiers calculate their prediction by taking as input features of different image translations, making each classifier learn independently, with the purpose of combining their outputs by sparse Multinomial Logistic Regression. This regression layer known as meta-learner helps to reduce the bias during pseudo label generation when performing self-supervised learning and improves the generalizability of the model by taking into consideration the contribution of each classifier. We evaluate our method on the standard UDA benchmarks, i.e. adapting GTA V and Synthia to Cityscapes, and achieve state-of-the-art results in the mean intersection over union metric. Extensive ablation experiments are reported to highlight the advantageous properties of our proposed UDA strategy.