 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Analysis of a Self-supervised Speech Representation Model
Paper and Code
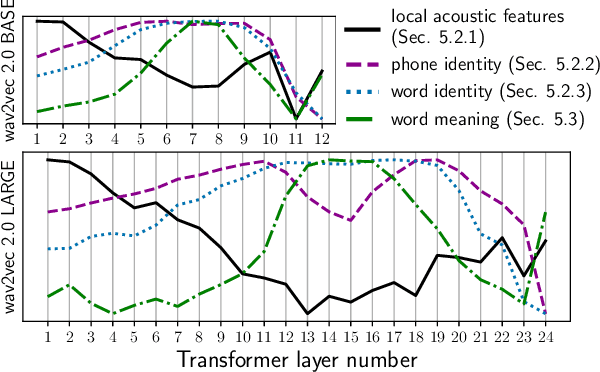
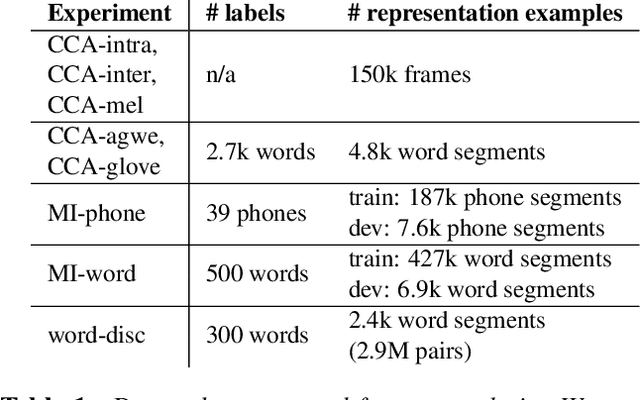
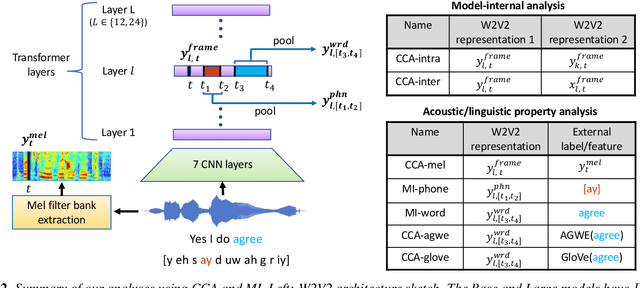

Recently proposed self-supervised learning approaches have been successful for pre-training speech representation models. The utility of these learned representations has been observed empirically, but not much has been studied about the type or extent of information encoded in the pre-trained representations themselves. Developing such insights can help understand the capabilities and limits of these models and enable the research community to more efficiently develop their usage for downstream applications. In this work, we begin to fill this gap by examining one recent and successful pre-trained model (wav2vec 2.0), via its intermediate representation vectors, using a suite of analysis tools. We use the metrics of canonical correlation, mutual information, and performance on simple downstream tasks with non-parametric probes, in order to (i) query for acoustic and linguistic information content, (ii) characterize the evolution of information across model layers, and (iii) understand how fine-tuning the model for automatic speech recognition (ASR) affects these observations. Our findings motivate modifying the fine-tuning protocol for ASR, which produces improved word error rates in a low-resource setting.