 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Breath Phase and Continuous Adventitious Sound Detection in Lung and Tracheal Sound Using Mixed Set Training and Domain Adaptation
Paper and Code
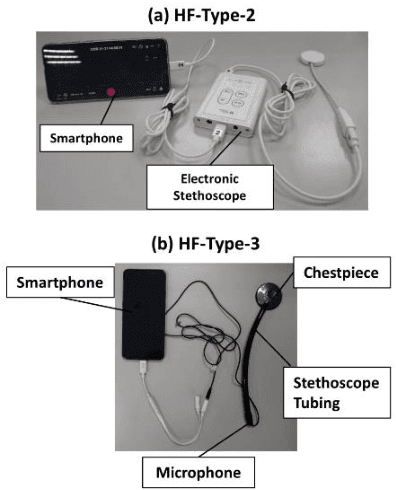
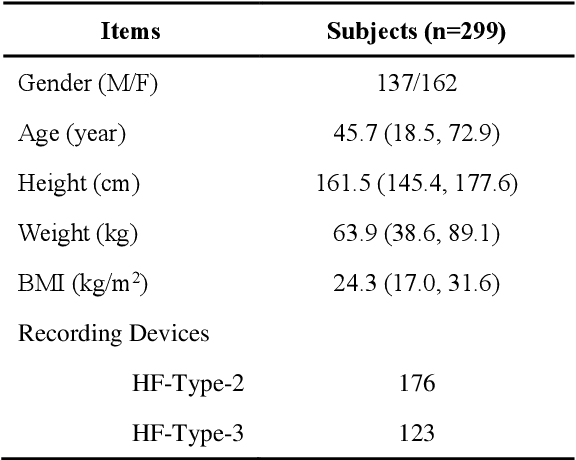
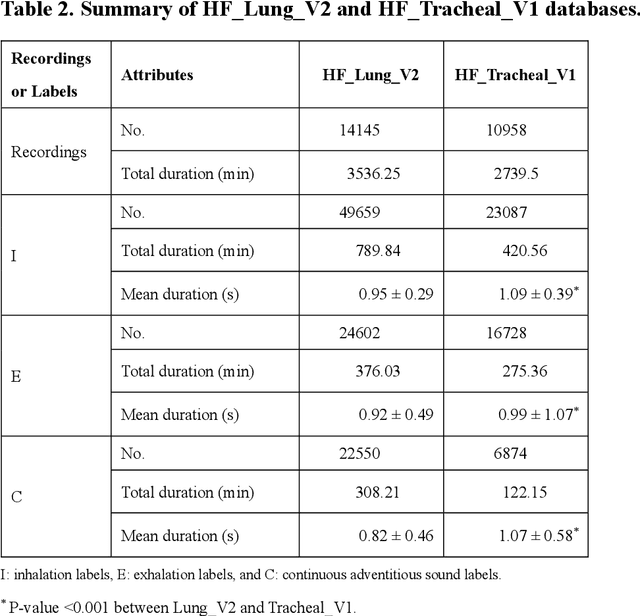
Previously, we established a lung sound database, HF_Lung_V2 and proposed convolutional bidirectional gated recurrent unit (CNN-BiGRU) models with adequate ability for inhalation, exhalation, continuous adventitious sound (CAS), and discontinuous adventitious sound detection in the lung sound. In this study, we proceeded to build a tracheal sound database, HF_Tracheal_V1, containing 11107 of 15-second tracheal sound recordings, 23087 inhalation labels, 16728 exhalation labels, and 6874 CAS labels. The tracheal sound in HF_Tracheal_V1 and the lung sound in HF_Lung_V2 were either combined or used alone to train the CNN-BiGRU models for respective lung and tracheal sound analysis. Different training strategies were investigated and compared: (1) using full training (training from scratch) to train the lung sound models using lung sound alone and train the tracheal sound models using tracheal sound alone, (2) using a mixed set that contains both the lung and tracheal sound to train the models, and (3) using domain adaptation that finetuned the pre-trained lung sound models with the tracheal sound data and vice versa. Results showed that the models trained only by lung sound performed poorly in the tracheal sound analysis and vice versa. However, the mixed set training and domain adaptation can improve the performance of exhalation and CAS detection in the lung sound, and inhalation, exhalation, and CAS detection in the tracheal sound compared to positive controls (lung models trained only by lung sound and vice versa). Especially, a model derived from the mixed set training prevails in the situation of killing two birds with one stone.