 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Q-learning: Deep Q-learning With State Values From Expert Examples
Paper and Code
Jun 29, 2021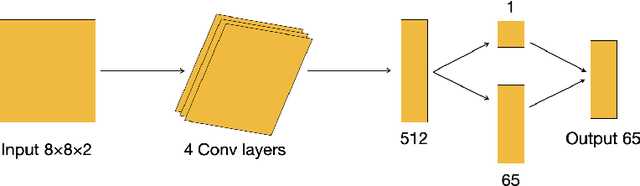
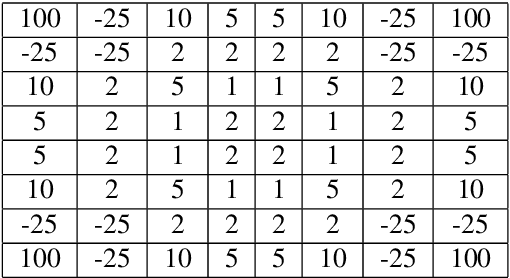
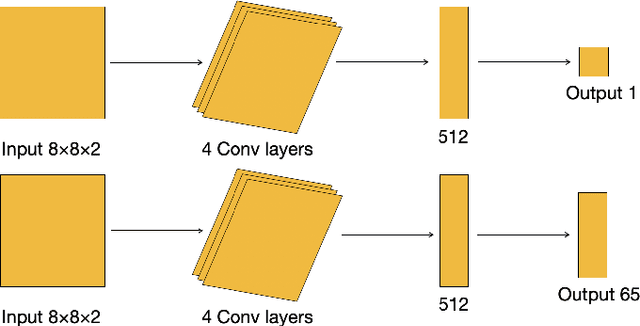
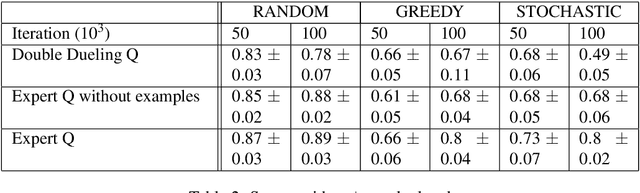
We propose a novel algorithm named Expert Q-learning. Expert Q-learning was inspired by Dueling Q-learning and aimed at incorporating the ideas from semi-supervised learning into reinforcement learning through splitting Q-values into state values and action advantages. Different from Generative Adversarial Imitation Learning and Deep Q-Learning from Demonstrations, the offline expert we have used only predicts the value of a state from {-1, 0, 1}, indicating whether this is a bad, neutral or good state. An expert network was designed in addition to the Q-network, which updates each time following the regular offline minibatch update whenever the expert example buffer is not empty. The Q-network plays the role of the advantage function only during the update. Our algorithm also keeps asynchronous copies of the Q-network and expert network, predicting the target values using the same manner as of Double Q-learning. We compared on the game of Othello our algorithm with the state-of-the-art Q-learning algorithm, which was a combination of Double Q-learning and Dueling Q-learning. The results showed that Expert Q-learning was indeed useful and more resistant to the overestimation bias of Q-learning. The baseline Q-learning algorithm exhibited unstable and suboptimal behavior, especially when playing against a stochastic player, whereas Expert Q-learning demonstrated more robust performance with higher scores. Expert Q-learning without using examples has also gained better results than the baseline algorithm when trained and tested against a fixed player. On the other hand, Expert Q-learning without examples cannot win against the baseline Q-learning algorithm in direct game competitions despite the fact that it has also shown the strength of reducing the overestimation bias.