 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Domain Mismatch in Low Resource Sequence-to-Sequence ASR Models using Hybrid Generated Pseudotranscripts
Paper and Code
Jun 14, 2021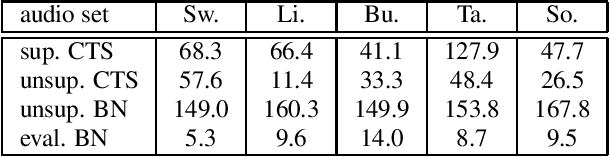
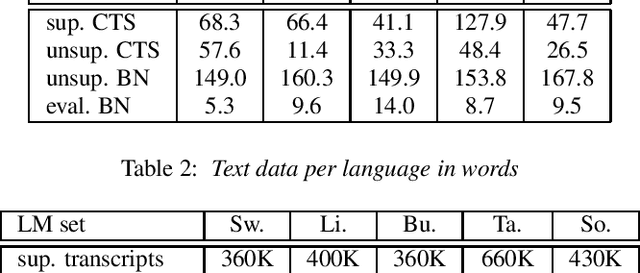
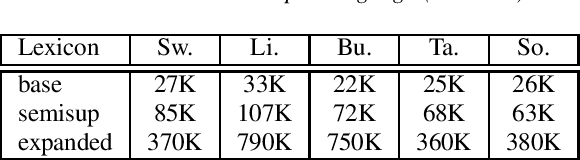
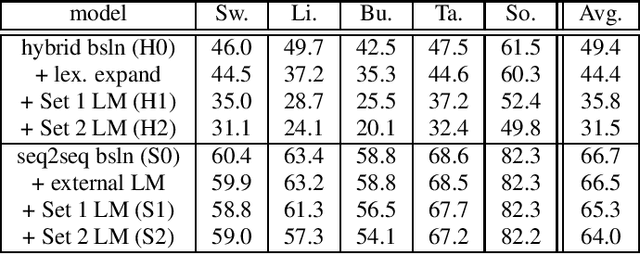
Sequence-to-sequence (seq2seq) models are competitive with hybrid models for automatic speech recognition (ASR) tasks when large amounts of training data are available. However, data sparsity and domain adaptation are more problematic for seq2seq models than their hybrid counterparts. We examine corpora of five languages from the IARPA MATERIAL program where the transcribed data is conversational telephone speech (CTS) and evaluation data is broadcast news (BN). We show that there is a sizable initial gap in such a data condition between hybrid and seq2seq models, and the hybrid model is able to further improve through the use of additional language model (LM) data. We use an additional set of untranscribed data primarily in the BN domain for semisupervised training. In semisupervised training, a seed model trained on transcribed data generates hypothesized transcripts for unlabeled domain-matched data for further training. By using a hybrid model with an expanded language model for pseudotranscription, we are able to improve our seq2seq model from an average word error rate (WER) of 66.7% across all five languages to 29.0% WER. While this puts the seq2seq model at a competitive operating point, hybrid models are still able to use additional LM data to maintain an advantage.