 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Various Tokenizers for Arabic Text Classification
Paper and Code
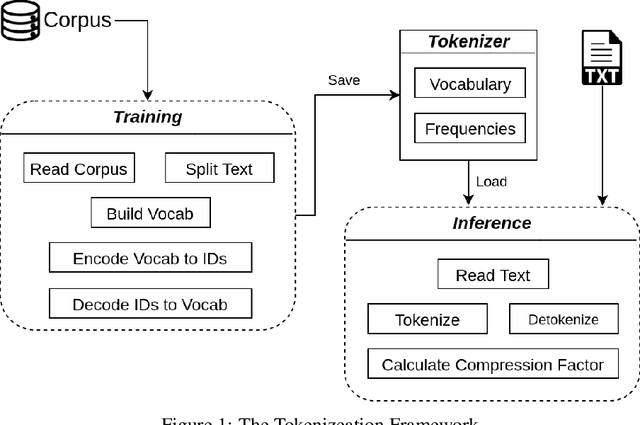

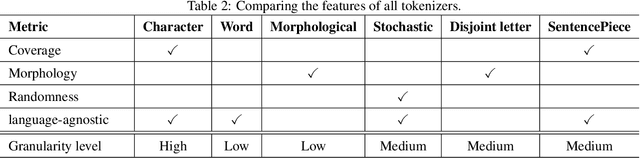
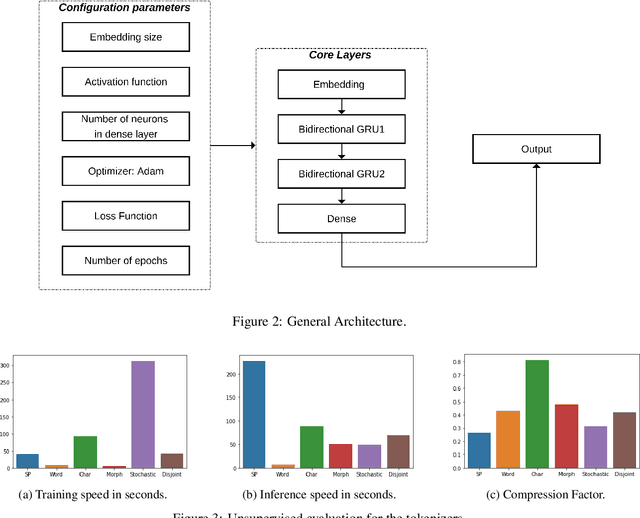
The first step in any NLP pipeline is learning word vector representations. However, given a large text corpus, representing all the words is not efficient. In the literature, many tokenization algorithms have emerged to tackle this problem by creating subwords which in turn limits the vocabulary size in any text corpus. However such algorithms are mostly language-agnostic and lack a proper way of capturing meaningful tokens. Not to mention the difficulty of evaluating such techniques in practice. In this paper, we introduce three new tokenization algorithms for Arabic and compare them to three other baselines using unsupervised evaluations. In addition to that, we compare all the six algorithms by evaluating them on three tasks which are sentiment analysis, news classification and poetry classification. Our experiments show that the performance of such tokenization algorithms depends on the size of the dataset, type of the task, and the amount of morphology that exists in the dataset.