 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelection of Source Images Heavily Influences the Effectiveness of Adversarial Attacks
Paper and Code
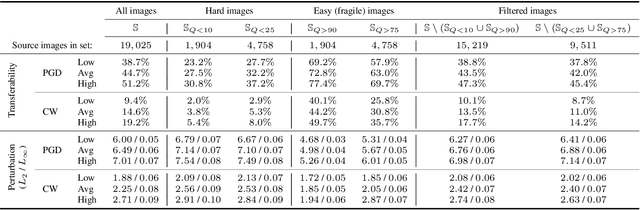
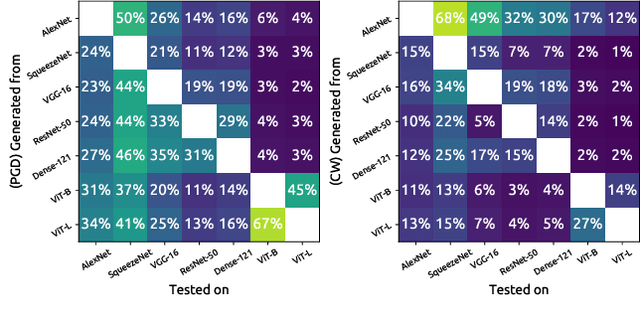
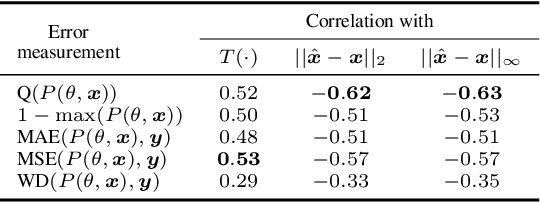
Although the adoption rate of deep neural networks (DNNs) has tremendously increased in recent years, a solution for their vulnerability against adversarial examples has not yet been found. As a result, substantial research efforts are dedicated to fix this weakness, with many studies typically using a subset of source images to generate adversarial examples, treating every image in this subset as equal. We demonstrate that, in fact, not every source image is equally suited for this kind of assessment. To do so, we devise a large-scale model-to-model transferability scenario for which we meticulously analyze the properties of adversarial examples, generated from every suitable source image in ImageNet by making use of two of the most frequently deployed attacks. In this transferability scenario, which involves seven distinct DNN models, including the recently proposed vision transformers, we reveal that it is possible to have a difference of up to $12.5\%$ in model-to-model transferability success, $1.01$ in average $L_2$ perturbation, and $0.03$ ($8/225$) in average $L_{\infty}$ perturbation when $1,000$ source images are sampled randomly among all suitable candidates. We then take one of the first steps in evaluating the robustness of images used to create adversarial examples, proposing a number of simple but effective methods to identify unsuitable source images, thus making it possible to mitigate extreme cases in experimentation and support high-quality benchmarking.