 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Social Welfare While Preserving Autonomy via a Pareto Mediator
Paper and Code
Jun 07, 2021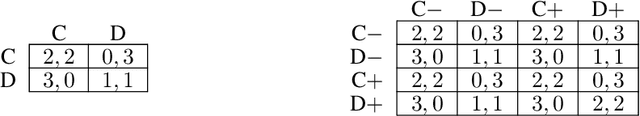
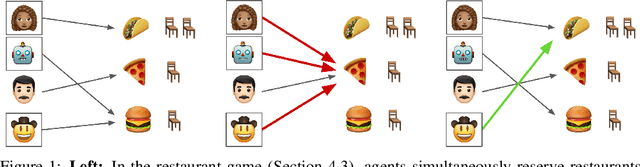
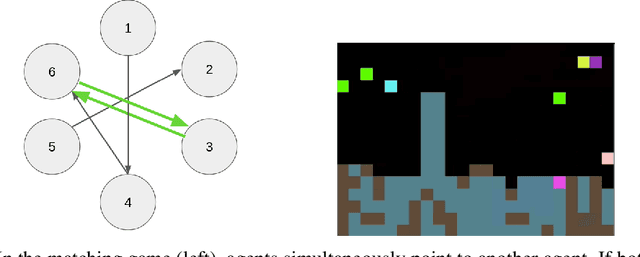

Machine learning algorithms often make decisions on behalf of agents with varied and sometimes conflicting interests. In domains where agents can choose to take their own action or delegate their action to a central mediator, an open question is how mediators should take actions on behalf of delegating agents. The main existing approach uses delegating agents to punish non-delegating agents in an attempt to get all agents to delegate, which tends to be costly for all. We introduce a Pareto Mediator which aims to improve outcomes for delegating agents without making any of them worse off. Our experiments in random normal form games, a restaurant recommendation game, and a reinforcement learning sequential social dilemma show that the Pareto Mediator greatly increases social welfare. Also, even when the Pareto Mediator is based on an incorrect model of agent utility, performance gracefully degrades to the pre-intervention level, due to the individual autonomy preserved by the voluntary mediator.