 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching keyword spotters to spot new keywords with limited examples
Paper and Code
Jun 04, 2021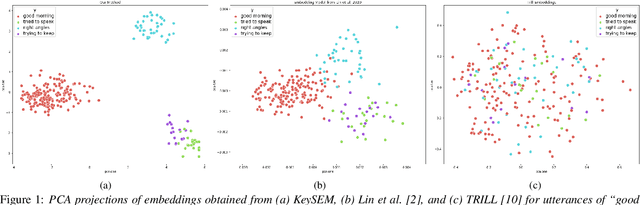
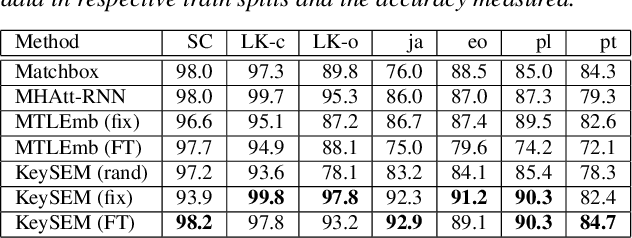
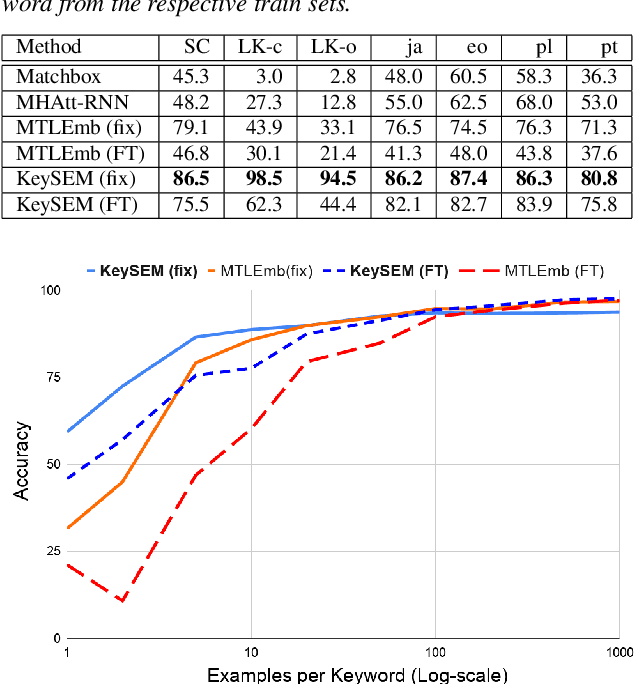
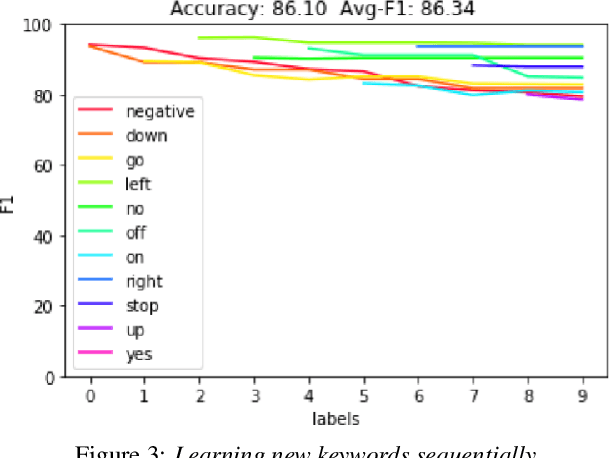
Learning to recognize new keywords with just a few examples is essential for personalizing keyword spotting (KWS) models to a user's choice of keywords. However, modern KWS models are typically trained on large datasets and restricted to a small vocabulary of keywords, limiting their transferability to a broad range of unseen keywords. Towards easily customizable KWS models, we present KeySEM (Keyword Speech EMbedding), a speech embedding model pre-trained on the task of recognizing a large number of keywords. Speech representations offered by KeySEM are highly effective for learning new keywords from a limited number of examples. Comparisons with a diverse range of related work across several datasets show that our method achieves consistently superior performance with fewer training examples. Although KeySEM was pre-trained only on English utterances, the performance gains also extend to datasets from four other languages indicating that KeySEM learns useful representations well aligned with the task of keyword spotting. Finally, we demonstrate KeySEM's ability to learn new keywords sequentially without requiring to re-train on previously learned keywords. Our experimental observations suggest that KeySEM is well suited to on-device environments where post-deployment learning and ease of customization are often desirable.