 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study of Spanish Text Transformations for Twitter Sentiment Analysis
Paper and Code
Jun 03, 2021
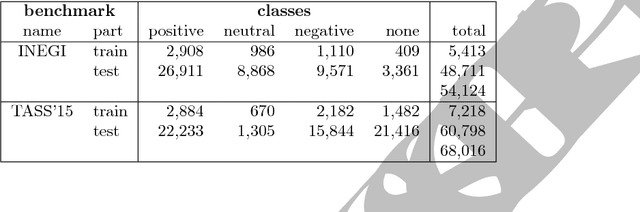
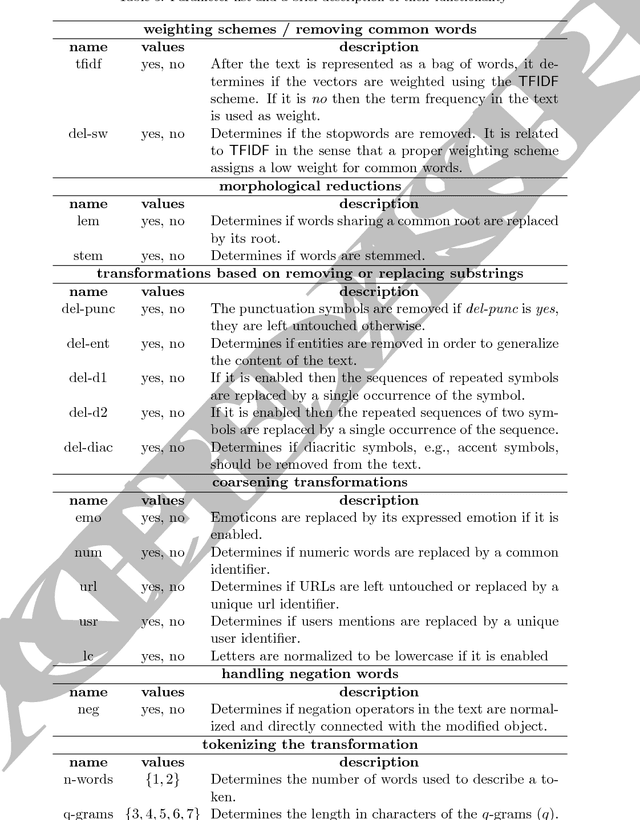
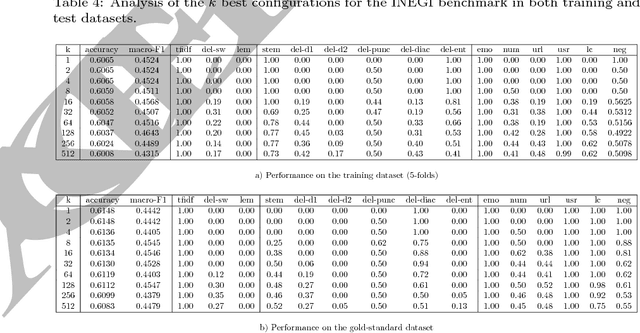
Sentiment analysis is a text mining task that determines the polarity of a given text, i.e., its positiveness or negativeness. Recently, it has received a lot of attention given the interest in opinion mining in micro-blogging platforms. These new forms of textual expressions present new challenges to analyze text given the use of slang, orthographic and grammatical errors, among others. Along with these challenges, a practical sentiment classifier should be able to handle efficiently large workloads. The aim of this research is to identify which text transformations (lemmatization, stemming, entity removal, among others), tokenizers (e.g., words $n$-grams), and tokens weighting schemes impact the most the accuracy of a classifier (Support Vector Machine) trained on two Spanish corpus. The methodology used is to exhaustively analyze all the combinations of the text transformations and their respective parameters to find out which characteristics the best performing classifiers have in common. Furthermore, among the different text transformations studied, we introduce a novel approach based on the combination of word based $n$-grams and character based $q$-grams. The results show that this novel combination of words and characters produces a classifier that outperforms the traditional word based combination by $11.17\%$ and $5.62\%$ on the INEGI and TASS'15 dataset, respectively.