 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit Phase Retrieval
Paper and Code
Jun 04, 2021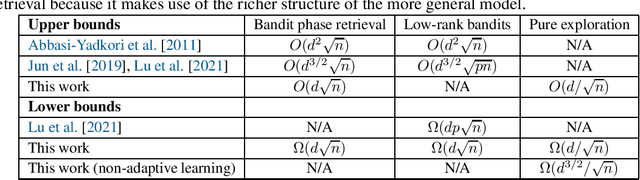
We study a bandit version of phase retrieval where the learner chooses actions $(A_t)_{t=1}^n$ in the $d$-dimensional unit ball and the expected reward is $\langle A_t, \theta_\star\rangle^2$ where $\theta_\star \in \mathbb R^d$ is an unknown parameter vector. We prove that the minimax cumulative regret in this problem is $\smash{\tilde \Theta(d \sqrt{n})}$, which improves on the best known bounds by a factor of $\smash{\sqrt{d}}$. We also show that the minimax simple regret is $\smash{\tilde \Theta(d / \sqrt{n})}$ and that this is only achievable by an adaptive algorithm. Our analysis shows that an apparently convincing heuristic for guessing lower bounds can be misleading and that uniform bounds on the information ratio for information-directed sampling are not sufficient for optimal regret.