 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-BERT -- Model for Sentiment Analysis of Micro-blogs Integrating Topic Model and BERT
Paper and Code
Jun 02, 2021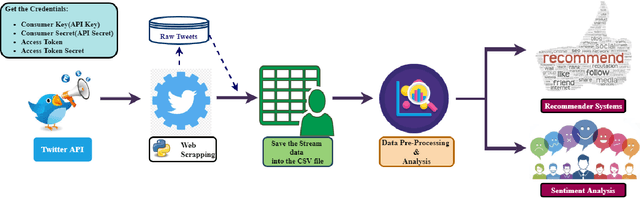
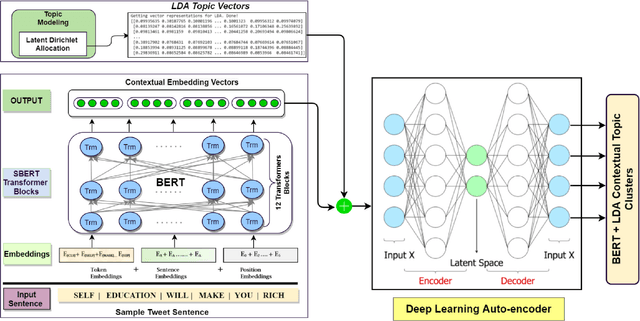
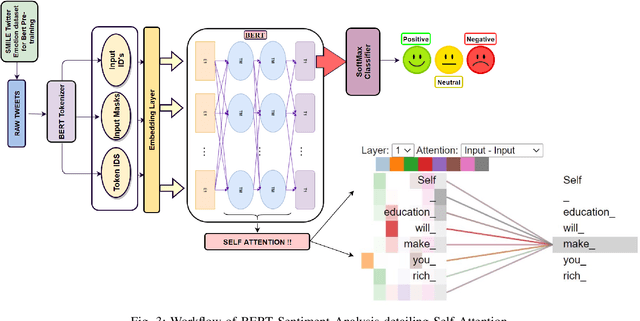
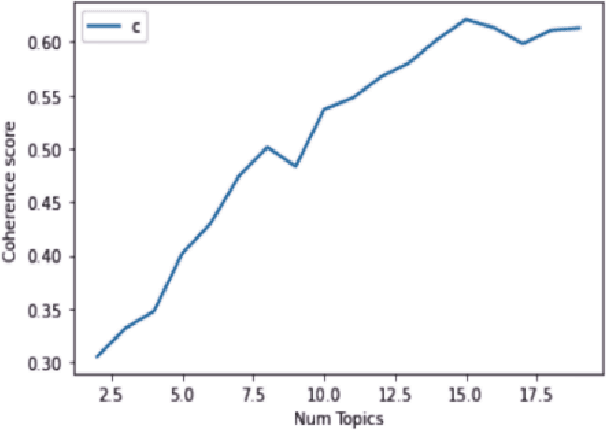
Sentiment analysis (SA) has become an extensive research area in recent years impacting diverse fields including ecommerce, consumer business, and politics, driven by increasing adoption and usage of social media platforms. It is challenging to extract topics and sentiments from unsupervised short texts emerging in such contexts, as they may contain figurative words, strident data, and co-existence of many possible meanings for a single word or phrase, all contributing to obtaining incorrect topics. Most prior research is based on a specific theme/rhetoric/focused-content on a clean dataset. In the work reported here, the effectiveness of BERT(Bidirectional Encoder Representations from Transformers) in sentiment classification tasks from a raw live dataset taken from a popular microblogging platform is demonstrated. A novel T-BERT framework is proposed to show the enhanced performance obtainable by combining latent topics with contextual BERT embeddings. Numerical experiments were conducted on an ensemble with about 42000 datasets using NimbleBox.ai platform with a hardware configuration consisting of Nvidia Tesla K80(CUDA), 4 core CPU, 15GB RAM running on an isolated Google Cloud Platform instance. The empirical results show that the model improves in performance while adding topics to BERT and an accuracy rate of 90.81% on sentiment classification using BERT with the proposed approach.