 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the constraints of multimodal fusion: case study in Weakly-Supervised Audio-Visual Video Parsing
Paper and Code
May 30, 2021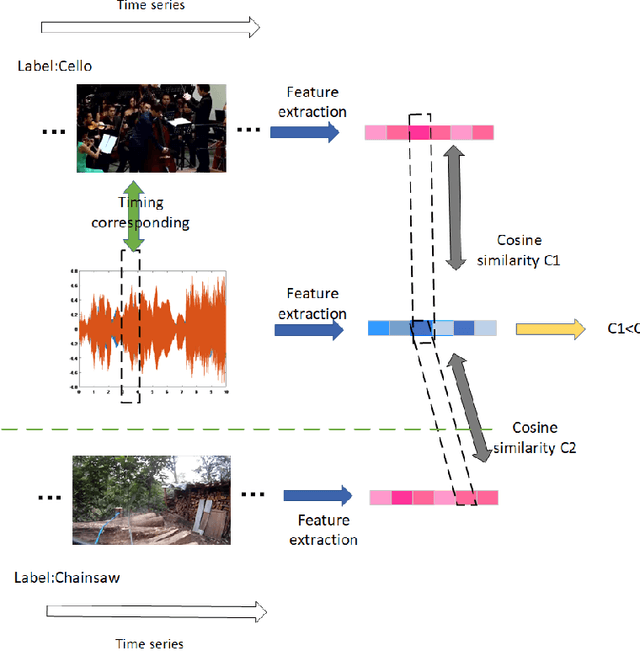

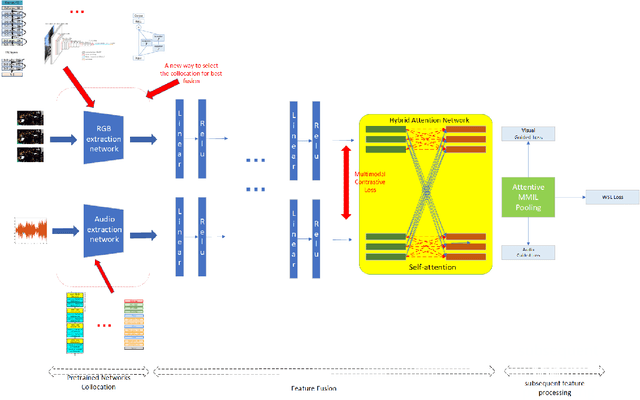
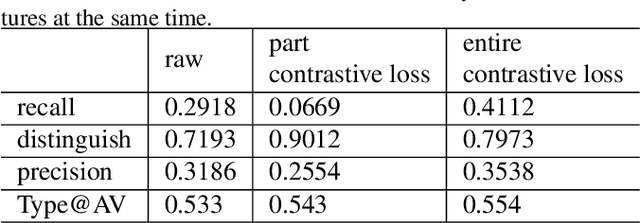
For multimodal tasks, a good feature extraction network should extract information as much as possible and ensure that the extracted feature embedding and other modal feature embedding have an excellent mutual understanding. The latter is often more critical in feature fusion than the former. Therefore, selecting the optimal feature extraction network collocation is a very important subproblem in multimodal tasks. Most of the existing studies ignore this problem or adopt an ergodic approach. This problem is modeled as an optimization problem in this paper. A novel method is proposed to convert the optimization problem into an issue of comparative upper bounds by referring to the general practice of extreme value conversion in mathematics. Compared with the traditional method, it reduces the time cost. Meanwhile, aiming at the common problem that the feature similarity and the feature semantic similarity are not aligned in the multimodal time-series problem, we refer to the idea of contrast learning and propose a multimodal time-series contrastive loss(MTSC). Based on the above issues, We demonstrated the feasibility of our approach in the audio-visual video parsing task. Substantial analyses verify that our methods promote the fusion of different modal features.