 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training
Paper and Code
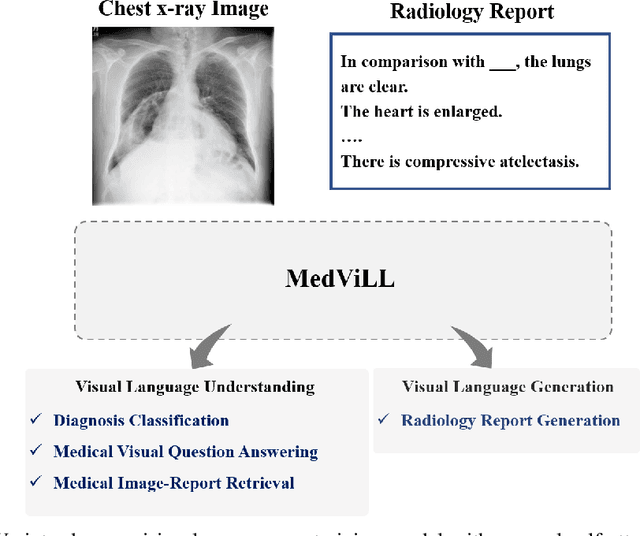

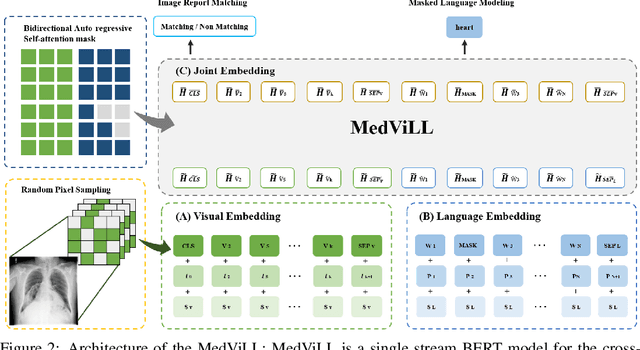
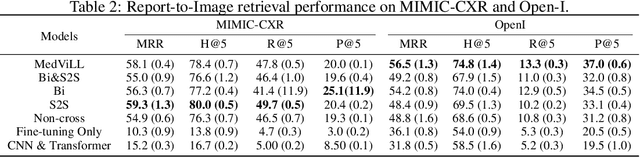
Recently a number of studies demonstrated impressive performance on diverse vision-language multi-modal tasks such as image captioning and visual question answering by extending the BERT architecture with multi-modal pre-training objectives. In this work we explore a broad set of multi-modal representation learning tasks in the medical domain, specifically using radiology images and the unstructured report. We propose Medical Vision Language Learner (MedViLL) which adopts a Transformer-based architecture combined with a novel multimodal attention masking scheme to maximize generalization performance for both vision-language understanding tasks (image-report retrieval, disease classification, medical visual question answering) and vision-language generation task (report generation). By rigorously evaluating the proposed model on four downstream tasks with two chest X-ray image datasets (MIMIC-CXR and Open-I), we empirically demonstrate the superior downstream task performance of MedViLL against various baselines including task-specific architectures.