 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaylor saves for later: disentanglement for video prediction using Taylor representation
Paper and Code
May 24, 2021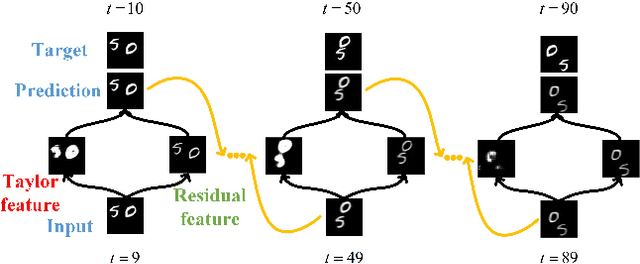
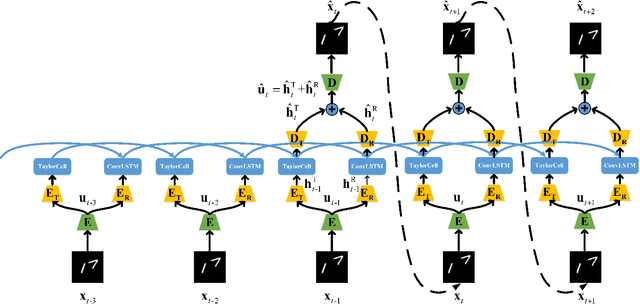
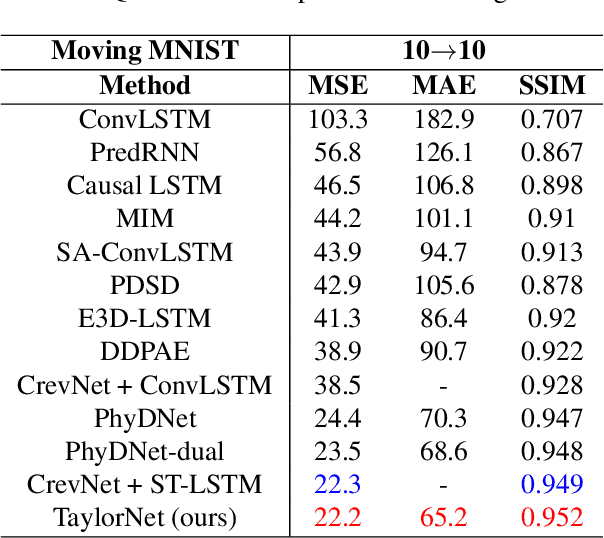
Video prediction is a challenging task with wide application prospects in meteorology and robot systems. Existing works fail to trade off short-term and long-term prediction performances and extract robust latent dynamics laws in video frames. We propose a two-branch seq-to-seq deep model to disentangle the Taylor feature and the residual feature in video frames by a novel recurrent prediction module (TaylorCell) and residual module. TaylorCell can expand the video frames' high-dimensional features into the finite Taylor series to describe the latent laws. In TaylorCell, we propose the Taylor prediction unit (TPU) and the memory correction unit (MCU). TPU employs the first input frame's derivative information to predict the future frames, avoiding error accumulation. MCU distills all past frames' information to correct the predicted Taylor feature from TPU. Correspondingly, the residual module extracts the residual feature complementary to the Taylor feature. On three generalist datasets (Moving MNIST, TaxiBJ, Human 3.6), our model outperforms or reaches state-of-the-art models, and ablation experiments demonstrate the effectiveness of our model in long-term prediction.