 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-Model Collaborative Learning of Neural Networks
Paper and Code
May 20, 2021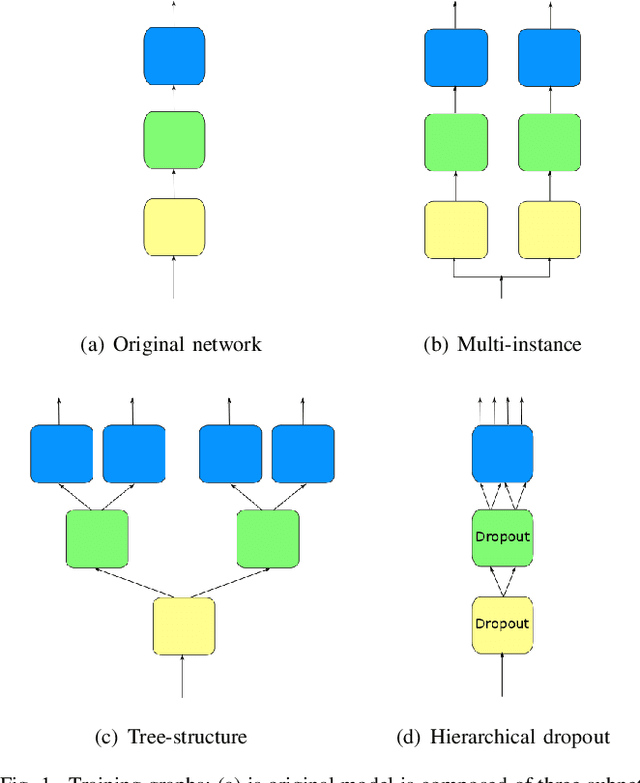
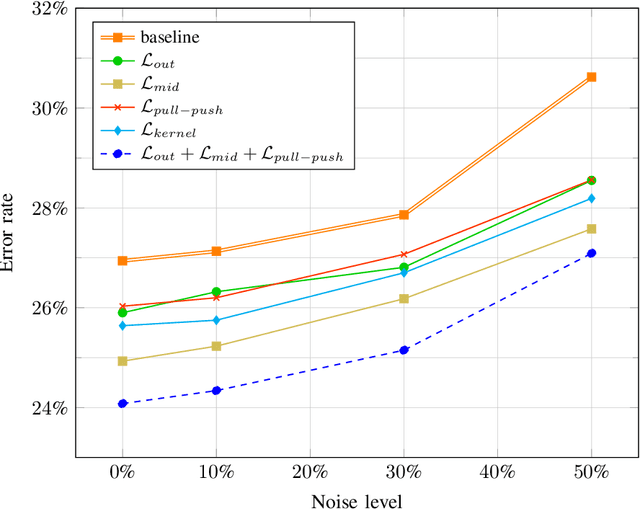
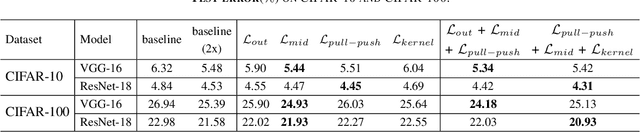
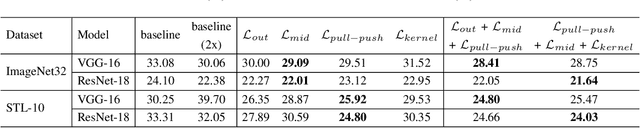
Recently, collaborative learning proposed by Song and Chai has achieved remarkable improvements in image classification tasks by simultaneously training multiple classifier heads. However, huge memory footprints required by such multi-head structures may hinder the training of large-capacity baseline models. The natural question is how to achieve collaborative learning within a single network without duplicating any modules. In this paper, we propose four ways of collaborative learning among different parts of a single network with negligible engineering efforts. To improve the robustness of the network, we leverage the consistency of the output layer and intermediate layers for training under the collaborative learning framework. Besides, the similarity of intermediate representation and convolution kernel is also introduced to reduce the reduce redundant in a neural network. Compared to the method of Song and Chai, our framework further considers the collaboration inside a single model and takes smaller overhead. Extensive experiments on Cifar-10, Cifar-100, ImageNet32 and STL-10 corroborate the effectiveness of these four ways separately while combining them leads to further improvements. In particular, test errors on the STL-10 dataset are decreased by $9.28\%$ and $5.45\%$ for ResNet-18 and VGG-16 respectively. Moreover, our method is proven to be robust to label noise with experiments on Cifar-10 dataset. For example, our method has $3.53\%$ higher performance under $50\%$ noise ratio setting.