 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc2Dict: Information Extraction as Text Generation
Paper and Code
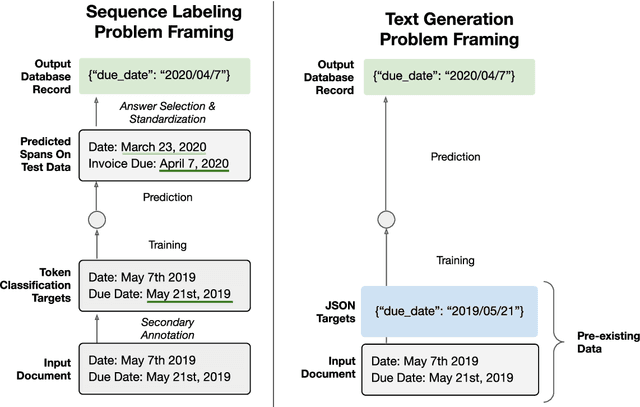
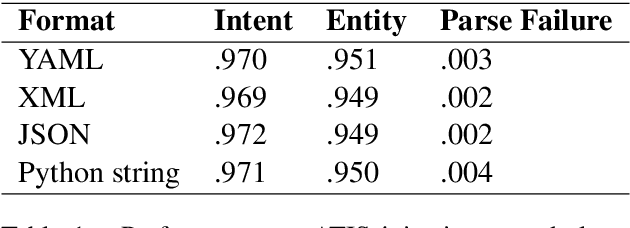
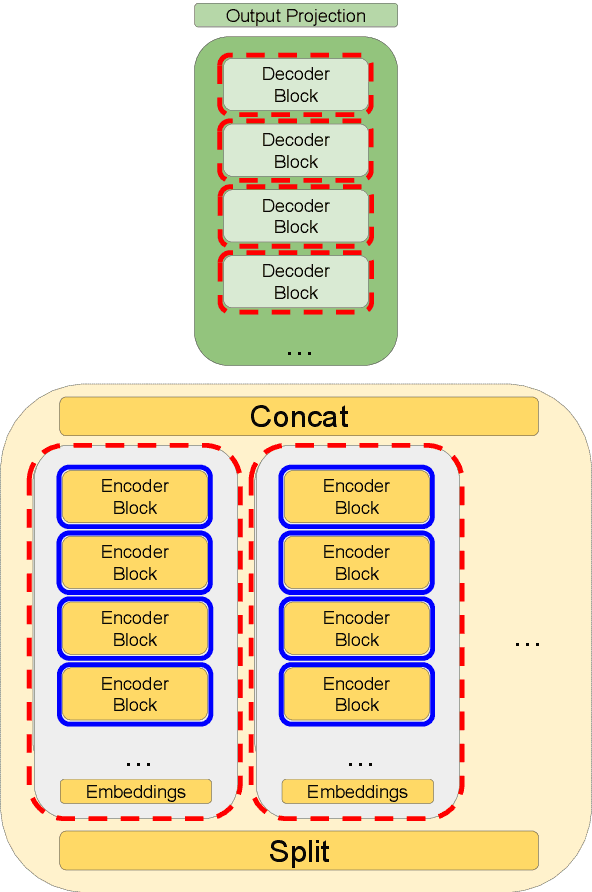
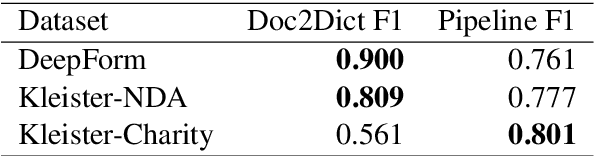
Typically, information extraction (IE) requires a pipeline approach: first, a sequence labeling model is trained on manually annotated documents to extract relevant spans; then, when a new document arrives, a model predicts spans which are then post-processed and standardized to convert the information into a database entry. We replace this labor-intensive workflow with a transformer language model trained on existing database records to directly generate structured JSON. Our solution removes the workload associated with producing token-level annotations and takes advantage of a data source which is generally quite plentiful (e.g. database records). As long documents are common in information extraction tasks, we use gradient checkpointing and chunked encoding to apply our method to sequences of up to 32,000 tokens on a single GPU. Our Doc2Dict approach is competitive with more complex, hand-engineered pipelines and offers a simple but effective baseline for document-level information extraction. We release our Doc2Dict model and code to reproduce our experiments and facilitate future work.