 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReturn-based Scaling: Yet Another Normalisation Trick for Deep RL
Paper and Code
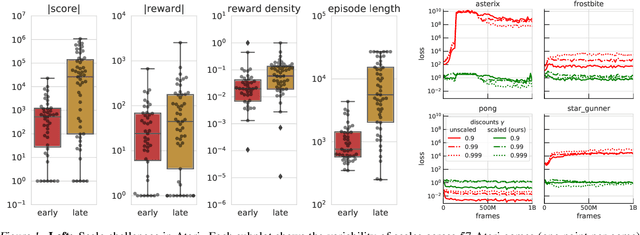
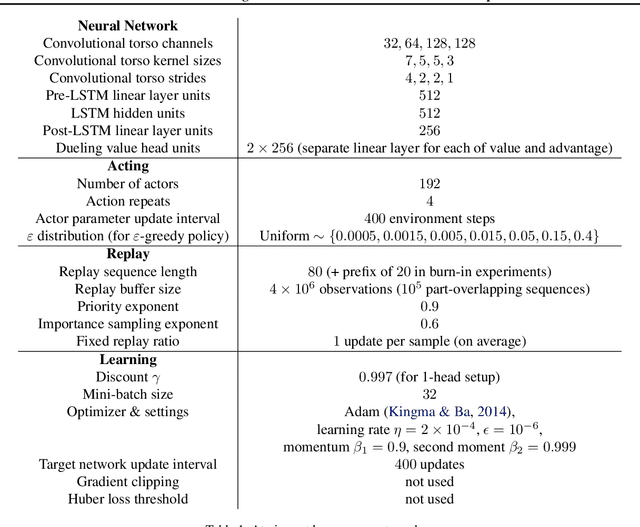
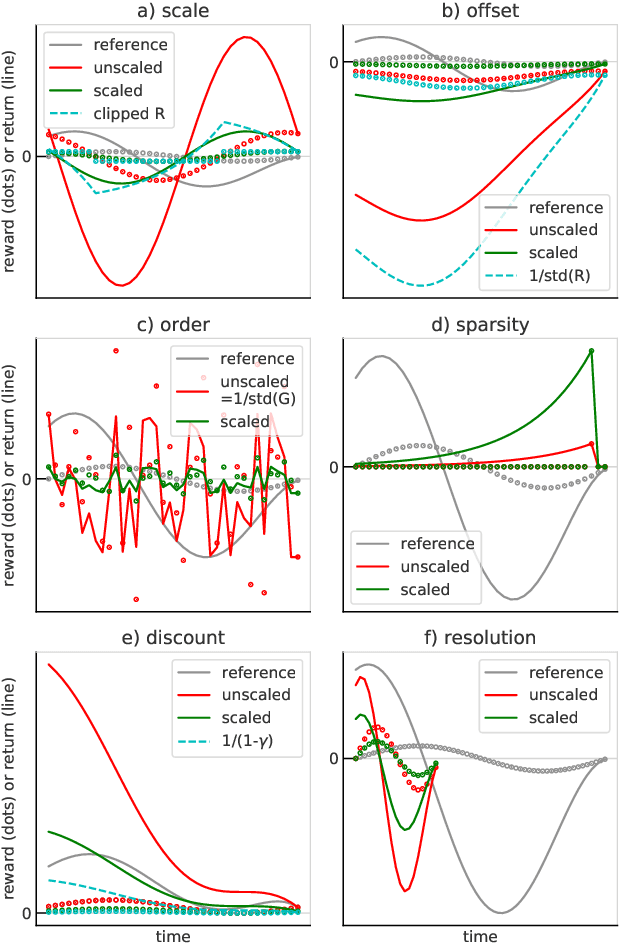
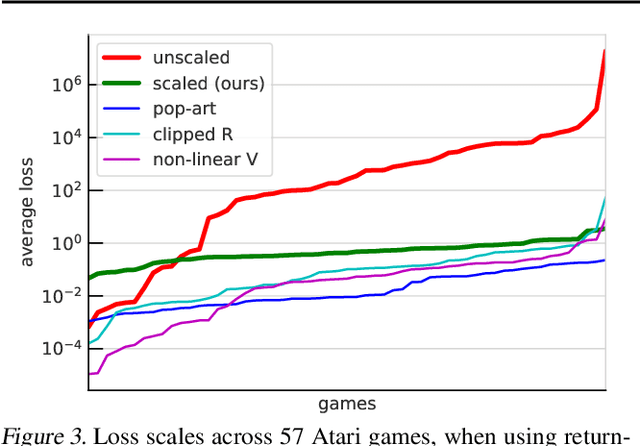
Scaling issues are mundane yet irritating for practitioners of reinforcement learning. Error scales vary across domains, tasks, and stages of learning; sometimes by many orders of magnitude. This can be detrimental to learning speed and stability, create interference between learning tasks, and necessitate substantial tuning. We revisit this topic for agents based on temporal-difference learning, sketch out some desiderata and investigate scenarios where simple fixes fall short. The mechanism we propose requires neither tuning, clipping, nor adaptation. We validate its effectiveness and robustness on the suite of Atari games. Our scaling method turns out to be particularly helpful at mitigating interference, when training a shared neural network on multiple targets that differ in reward scale or discounting.