 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Understanding for Autonomous Driving
Paper and Code
May 11, 2021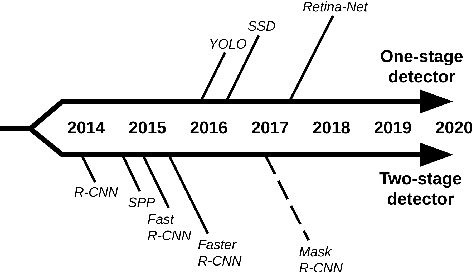

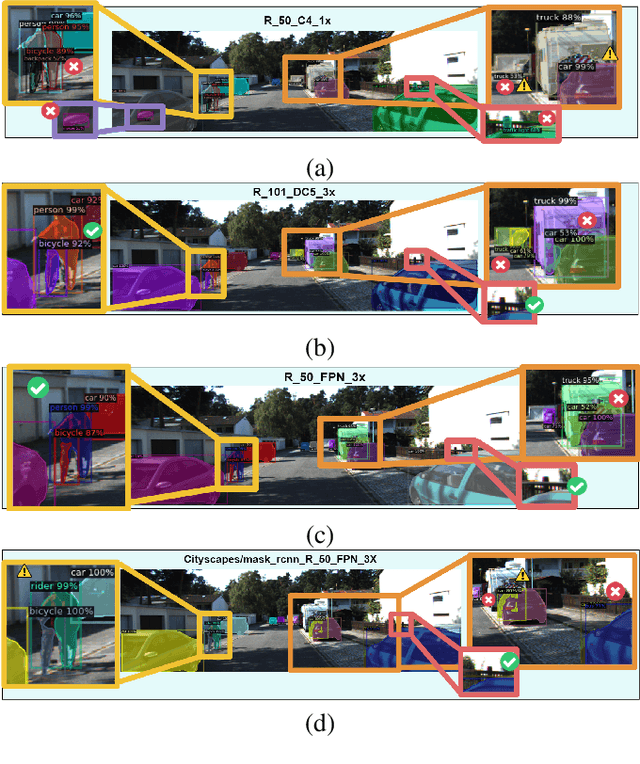
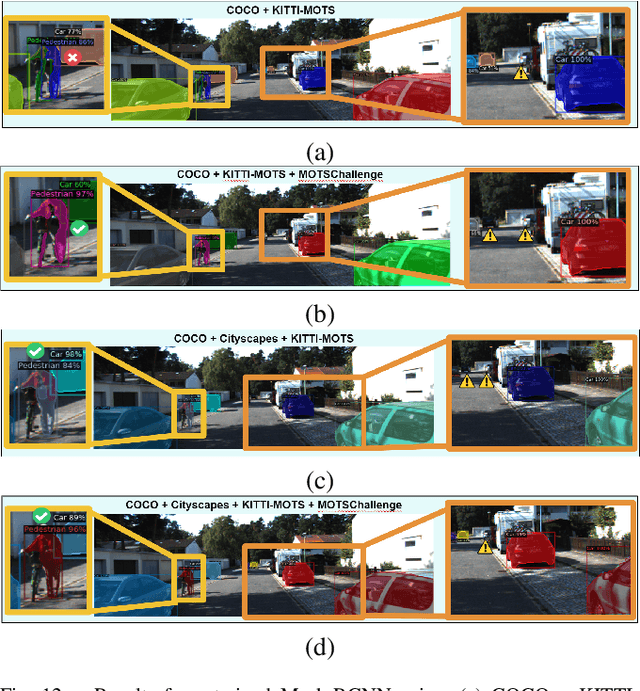
To detect and segment objects in images based on their content is one of the most active topics in the field of computer vision. Nowadays, this problem can be addressed using Deep Learning architectures such as Faster R-CNN or YOLO, among others. In this paper, we study the behaviour of different configurations of RetinaNet, Faster R-CNN and Mask R-CNN presented in Detectron2. First, we evaluate qualitatively and quantitatively (AP) the performance of the pre-trained models on KITTI-MOTS and MOTSChallenge datasets. We observe a significant improvement in performance after fine-tuning these models on the datasets of interest and optimizing hyperparameters. Finally, we run inference in unusual situations using out of context datasets, and present interesting results that help us understanding better the networks.