 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSCAN: Unsupervised Text Classification via Learning from Neighbors
Paper and Code
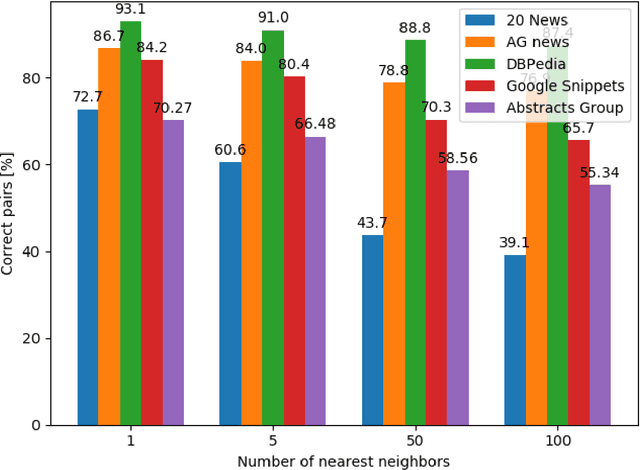
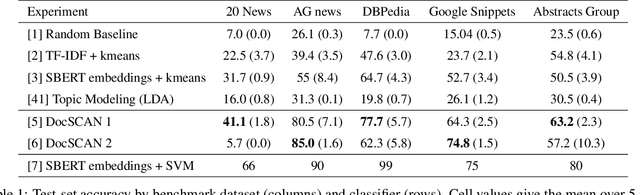

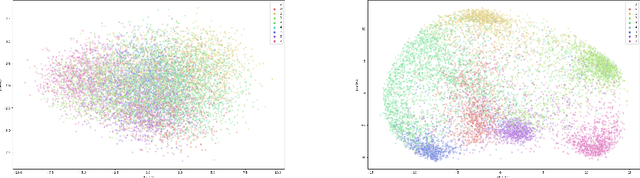
We introduce DocSCAN, a completely unsupervised text classification approach using Semantic Clustering by Adopting Nearest-Neighbors (SCAN). For each document, we obtain semantically informative vectors from a large pre-trained language model. Similar documents have proximate vectors, so neighbors in the representation space tend to share topic labels. Our learnable clustering approach uses pairs of neighboring datapoints as a weak learning signal. The proposed approach learns to assign classes to the whole dataset without provided ground-truth labels. On five topic classification benchmarks, we improve on various unsupervised baselines by a large margin. In datasets with relatively few and balanced outcome classes, DocSCAN approaches the performance of supervised classification. The method fails for other types of classification, such as sentiment analysis, pointing to important conceptual and practical differences between classifying images and texts.