 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Sentence Models Perform Better in Simultaneous Translation Using the Information Enhanced Decoding Strategy
Paper and Code
May 05, 2021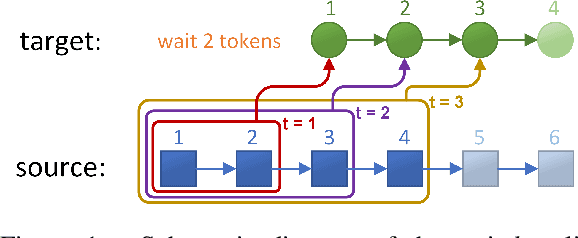
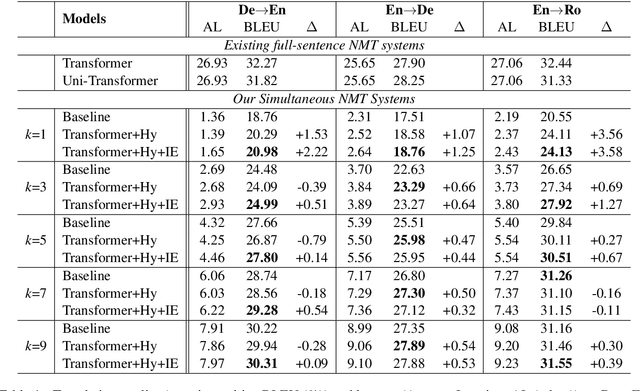
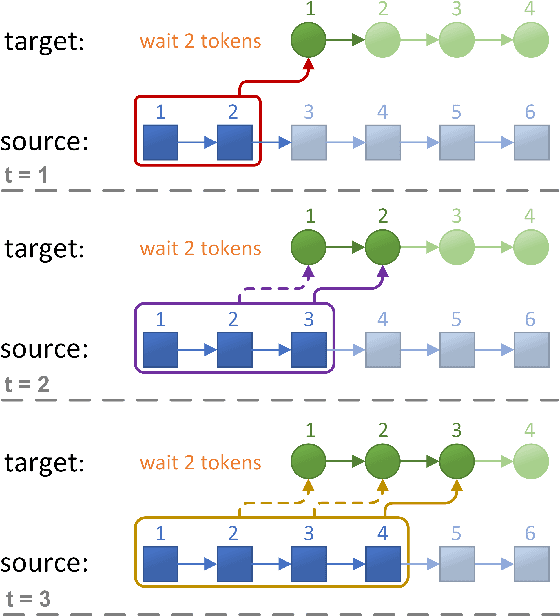
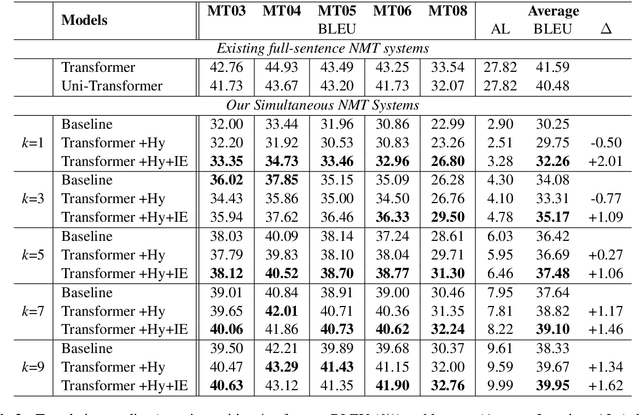
Simultaneous translation, which starts translating each sentence after receiving only a few words in source sentence, has a vital role in many scenarios. Although the previous prefix-to-prefix framework is considered suitable for simultaneous translation and achieves good performance, it still has two inevitable drawbacks: the high computational resource costs caused by the need to train a separate model for each latency $k$ and the insufficient ability to encode information because each target token can only attend to a specific source prefix. We propose a novel framework that adopts a simple but effective decoding strategy which is designed for full-sentence models. Within this framework, training a single full-sentence model can achieve arbitrary given latency and save computational resources. Besides, with the competence of the full-sentence model to encode the whole sentence, our decoding strategy can enhance the information maintained in the decoded states in real time. Experimental results show that our method achieves better translation quality than baselines on 4 directions: Zh$\rightarrow$En, En$\rightarrow$Ro and En$\leftrightarrow$De.