 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere and When: Space-Time Attention for Audio-Visual Explanations
Paper and Code
May 04, 2021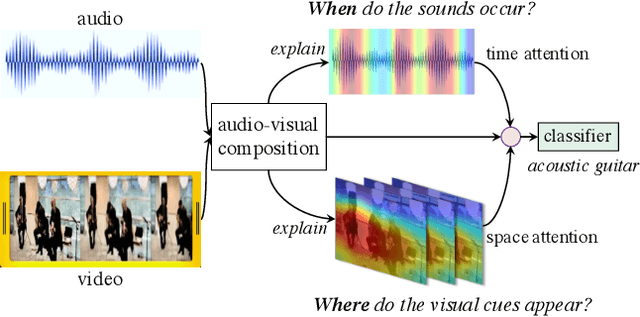
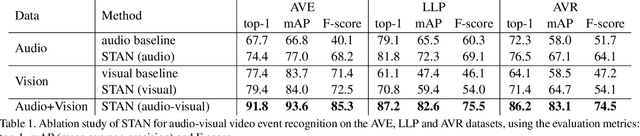
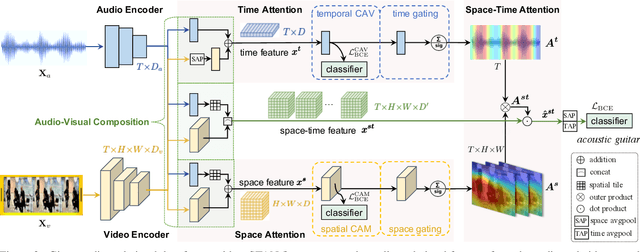
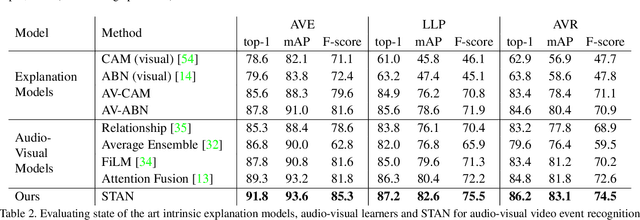
Explaining the decision of a multi-modal decision-maker requires to determine the evidence from both modalities. Recent advances in XAI provide explanations for models trained on still images. However, when it comes to modeling multiple sensory modalities in a dynamic world, it remains underexplored how to demystify the mysterious dynamics of a complex multi-modal model. In this work, we take a crucial step forward and explore learnable explanations for audio-visual recognition. Specifically, we propose a novel space-time attention network that uncovers the synergistic dynamics of audio and visual data over both space and time. Our model is capable of predicting the audio-visual video events, while justifying its decision by localizing where the relevant visual cues appear, and when the predicted sounds occur in videos. We benchmark our model on three audio-visual video event datasets, comparing extensively to multiple recent multi-modal representation learners and intrinsic explanation models. Experimental results demonstrate the clear superior performance of our model over the existing methods on audio-visual video event recognition. Moreover, we conduct an in-depth study to analyze the explainability of our model based on robustness analysis via perturbation tests and pointing games using human annotations.