 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Document Representations for Content-based Legal Literature Recommendations
Paper and Code
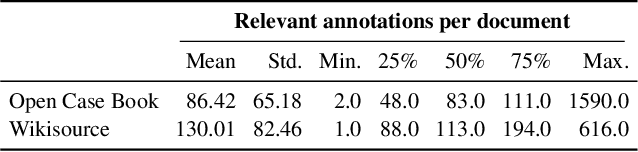
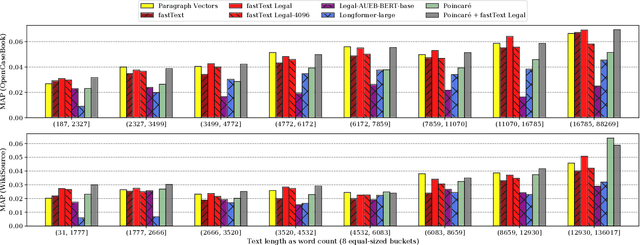
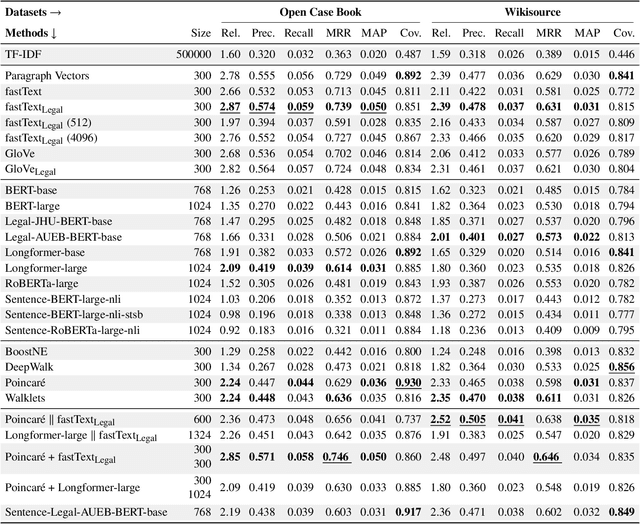
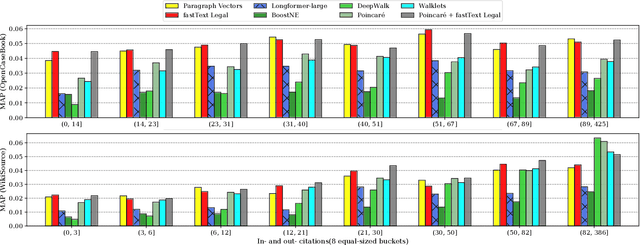
Recommender systems assist legal professionals in finding relevant literature for supporting their case. Despite its importance for the profession, legal applications do not reflect the latest advances in recommender systems and representation learning research. Simultaneously, legal recommender systems are typically evaluated in small-scale user study without any public available benchmark datasets. Thus, these studies have limited reproducibility. To address the gap between research and practice, we explore a set of state-of-the-art document representation methods for the task of retrieving semantically related US case law. We evaluate text-based (e.g., fastText, Transformers), citation-based (e.g., DeepWalk, Poincar\'e), and hybrid methods. We compare in total 27 methods using two silver standards with annotations for 2,964 documents. The silver standards are newly created from Open Case Book and Wikisource and can be reused under an open license facilitating reproducibility. Our experiments show that document representations from averaged fastText word vectors (trained on legal corpora) yield the best results, closely followed by Poincar\'e citation embeddings. Combining fastText and Poincar\'e in a hybrid manner further improves the overall result. Besides the overall performance, we analyze the methods depending on document length, citation count, and the coverage of their recommendations. We make our source code, models, and datasets publicly available at https://github.com/malteos/legal-document-similarity/.