 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT2MVS: Generative Pre-trained Transformer-2 for Multi-modal Video Summarization
Paper and Code
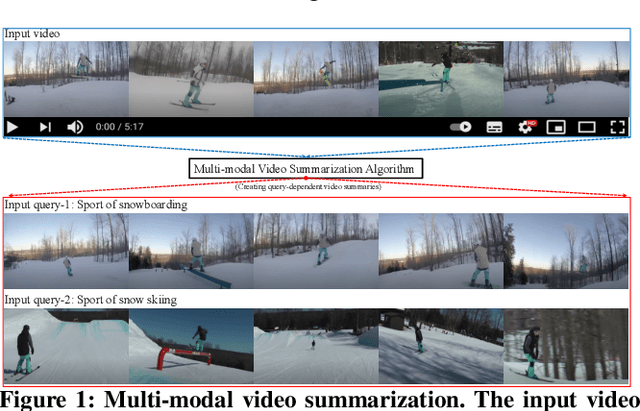
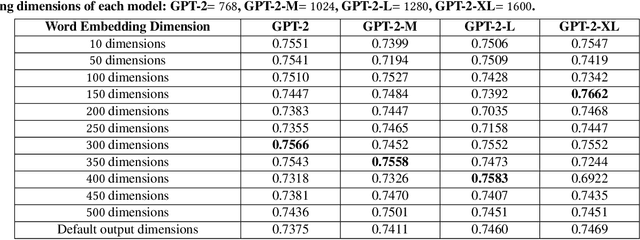
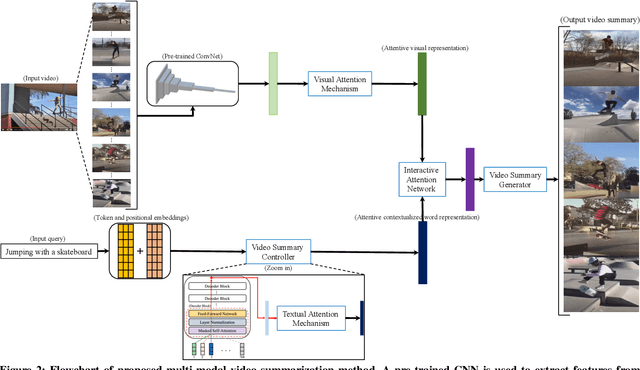
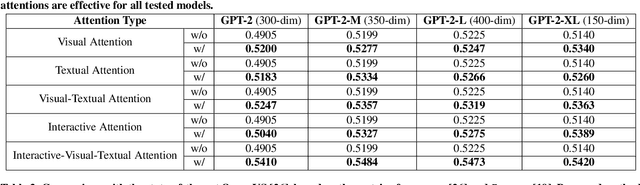
Traditional video summarization methods generate fixed video representations regardless of user interest. Therefore such methods limit users' expectations in content search and exploration scenarios. Multi-modal video summarization is one of the methods utilized to address this problem. When multi-modal video summarization is used to help video exploration, a text-based query is considered as one of the main drivers of video summary generation, as it is user-defined. Thus, encoding the text-based query and the video effectively are both important for the task of multi-modal video summarization. In this work, a new method is proposed that uses a specialized attention network and contextualized word representations to tackle this task. The proposed model consists of a contextualized video summary controller, multi-modal attention mechanisms, an interactive attention network, and a video summary generator. Based on the evaluation of the existing multi-modal video summarization benchmark, experimental results show that the proposed model is effective with the increase of +5.88% in accuracy and +4.06% increase of F1-score, compared with the state-of-the-art method.