 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than Meets The Eye: Semi-supervised Learning Under Non-IID Data
Paper and Code
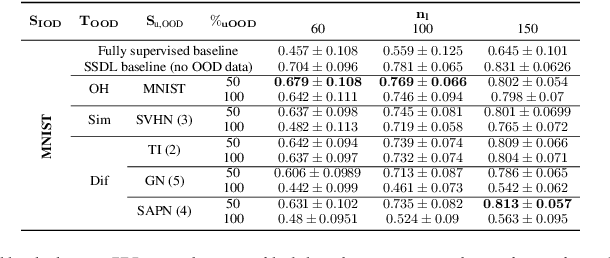
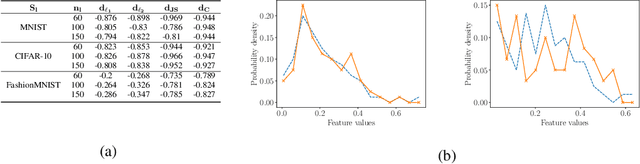
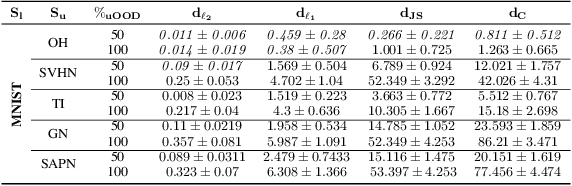
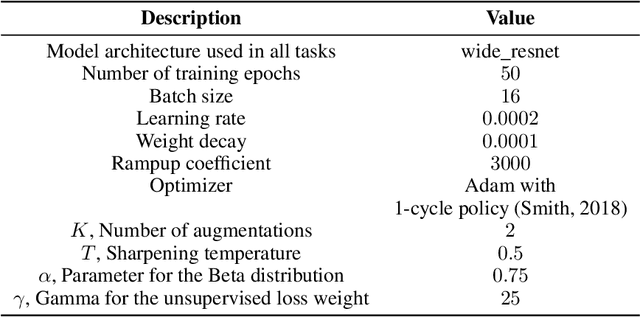
A common heuristic in semi-supervised deep learning (SSDL) is to select unlabelled data based on a notion of semantic similarity to the labelled data. For example, labelled images of numbers should be paired with unlabelled images of numbers instead of, say, unlabelled images of cars. We refer to this practice as semantic data set matching. In this work, we demonstrate the limits of semantic data set matching. We show that it can sometimes even degrade the performance for a state of the art SSDL algorithm. We present and make available a comprehensive simulation sandbox, called non-IID-SSDL, for stress testing an SSDL algorithm under different degrees of distribution mismatch between the labelled and unlabelled data sets. In addition, we demonstrate that simple density based dissimilarity measures in the feature space of a generic classifier offer a promising and more reliable quantitative matching criterion to select unlabelled data before SSDL training.