 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Better Performance of Position Encoding Variants for Transformer
Paper and Code
Apr 18, 2021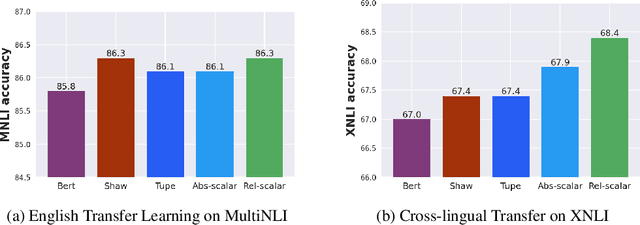

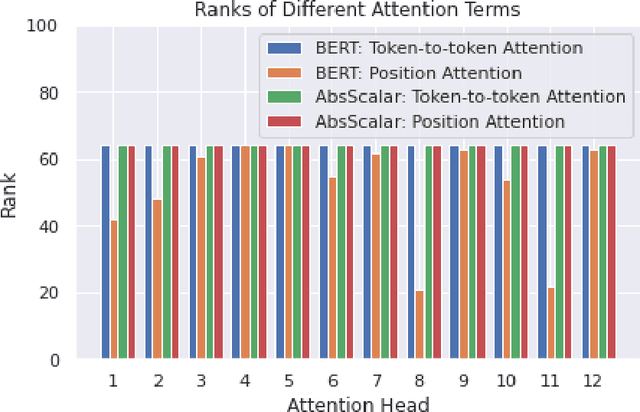

Transformers are state of the art models in NLP that map a given input sequence of vectors to an output sequence of vectors. However these models are permutation equivariant, and additive position embeddings to the input are used to supply the information about the order of the input tokens. Further, for some tasks, additional additive segment embeddings are used to denote different types of input sentences. Recent works proposed variations of positional encodings with relative position encodings achieving better performance. In this work, we do a systematic study comparing different position encodings and understanding the reasons for differences in their performance. We demonstrate a simple yet effective way to encode position and segment into the Transformer models. The proposed method performs on par with SOTA on GLUE, XTREME and WMT benchmarks while saving computation costs.