 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic maps and metrics for science Semantic maps and metrics for science using deep transformer encoders
Paper and Code
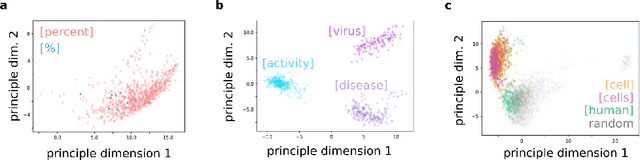
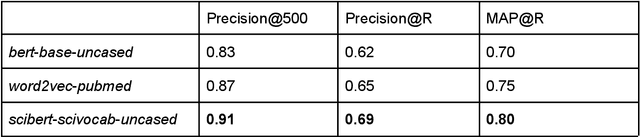
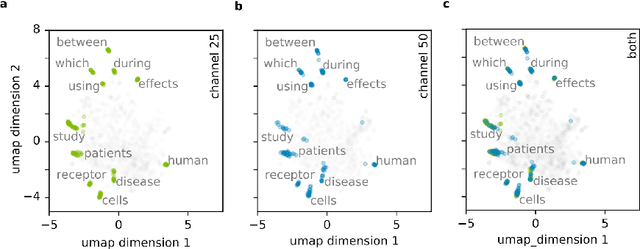
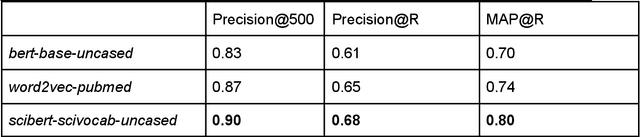
The growing deluge of scientific publications demands text analysis tools that can help scientists and policy-makers navigate, forecast and beneficially guide scientific research. Recent advances in natural language understanding driven by deep transformer networks offer new possibilities for mapping science. Because the same surface text can take on multiple and sometimes contradictory specialized senses across distinct research communities, sensitivity to context is critical for infometric applications. Transformer embedding models such as BERT capture shades of association and connotation that vary across the different linguistic contexts of any particular word or span of text. Here we report a procedure for encoding scientific documents with these tools, measuring their improvement over static word embeddings in a nearest-neighbor retrieval task. We find discriminability of contextual representations is strongly influenced by choice of pooling strategy for summarizing the high-dimensional network activations. Importantly, we note that fundamentals such as domain-matched training data are more important than state-of-the-art NLP tools. Yet state-of-the-art models did offer significant gains. The best approach we investigated combined domain-matched pretraining, sound pooling, and state-of-the-art deep transformer network encoders. Finally, with the goal of leveraging contextual representations from deep encoders, we present a range of measurements for understanding and forecasting research communities in science.