 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive spatial speech recognition maps based on simulated speech recognition experiments
Paper and Code
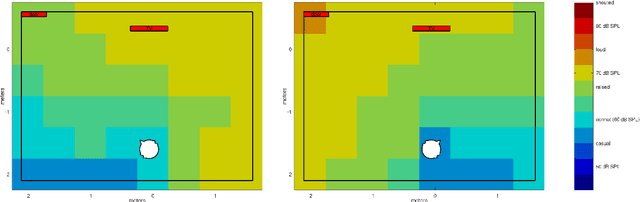
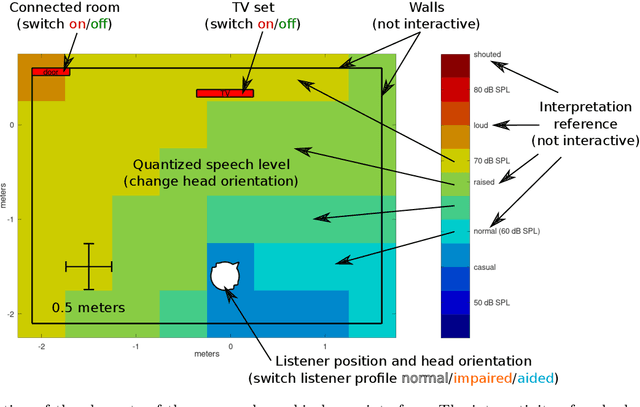


In their everyday life, the speech recognition performance of human listeners is influenced by diverse factors, such as the acoustic environment, the talker and listener positions, possibly impaired hearing, and optional hearing devices. Prediction models come closer to considering all required factors simultaneously to predict the individual speech recognition performance in complex acoustic environments. While such predictions may still not be sufficiently accurate for serious applications, they can already be performed and demand an accessible representation. In this contribution, an interactive representation of speech recognition performance is proposed, which focuses on the listeners head orientation and the spatial dimensions of an acoustic scene. A exemplary modeling toolchain, including an acoustic rendering model, a hearing device model, and a listener model, was used to generate a data set for demonstration purposes. Using the spatial speech recognition maps to explore this data set demonstrated the suitability of the approach to observe possibly relevant behavior. The proposed representation provides a suitable target to compare and validate different modeling approaches in ecologically relevant contexts. Eventually, it may serve as a tool to use validated prediction models in the design of spaces and devices which take speech communication into account.