 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis on Image Set Visual Question Answering
Paper and Code
Mar 31, 2021
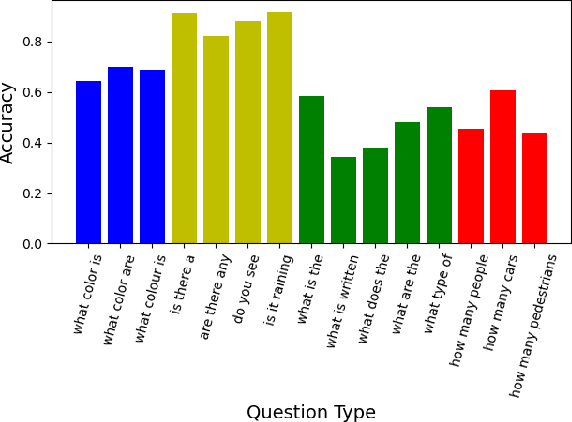
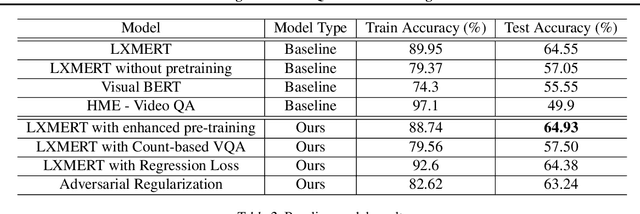

We tackle the challenge of Visual Question Answering in multi-image setting for the ISVQA dataset. Traditional VQA tasks have focused on a single-image setting where the target answer is generated from a single image. Image set VQA, however, comprises of a set of images and requires finding connection between images, relate the objects across images based on these connections and generate a unified answer. In this report, we work with 4 approaches in a bid to improve the performance on the task. We analyse and compare our results with three baseline models - LXMERT, HME-VideoQA and VisualBERT - and show that our approaches can provide a slight improvement over the baselines. In specific, we try to improve on the spatial awareness of the model and help the model identify color using enhanced pre-training, reduce language dependence using adversarial regularization, and improve counting using regression loss and graph based deduplication. We further delve into an in-depth analysis on the language bias in the ISVQA dataset and show how models trained on ISVQA implicitly learn to associate language more strongly with the final answer.