 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Invariance in Training Deep Neural Networks
Paper and Code
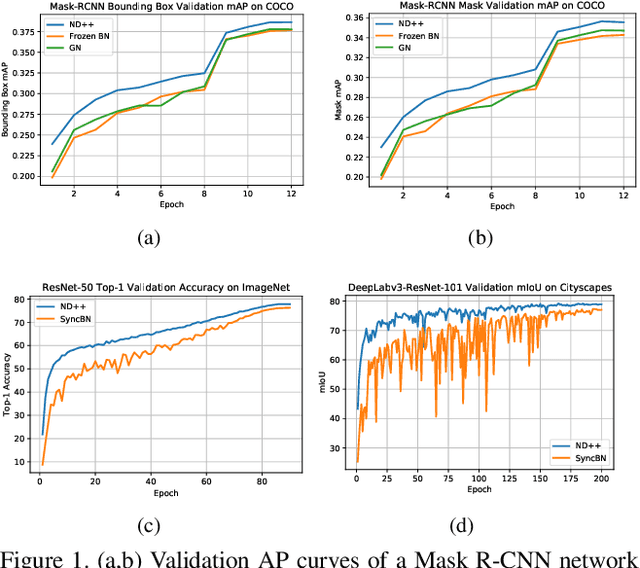
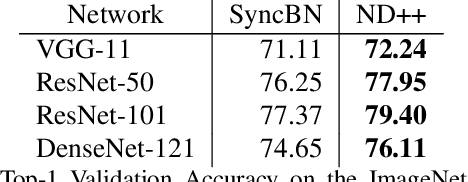
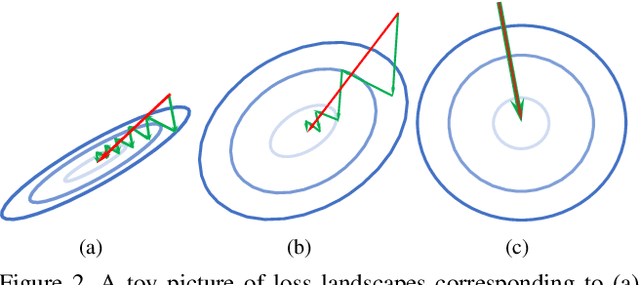

Inspired by two basic mechanisms in animal visual systems, we introduce a feature transform technique that imposes invariance properties in the training of deep neural networks. The resulting algorithm requires less parameter tuning, trains well with an initial learning rate 1.0, and easily generalizes to different tasks. We enforce scale invariance with local statistics in the data to align similar samples generated in diverse situations. To accelerate convergence, we enforce a GL(n)-invariance property with global statistics extracted from a batch that the gradient descent solution should remain invariant under basis change. Tested on ImageNet, MS COCO, and Cityscapes datasets, our proposed technique requires fewer iterations to train, surpasses all baselines by a large margin, seamlessly works on both small and large batch size training, and applies to different computer vision tasks of image classification, object detection, and semantic segmentation.